Microsoft DP-100 Designing and Implementing a Data Science Solution on Azure Exam Practice Test
Designing and Implementing a Data Science Solution on Azure Questions and Answers
You need to define a process for penalty event detection.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

You need to implement a model development strategy to determine a user’s tendency to respond to an ad.
Which technique should you use?
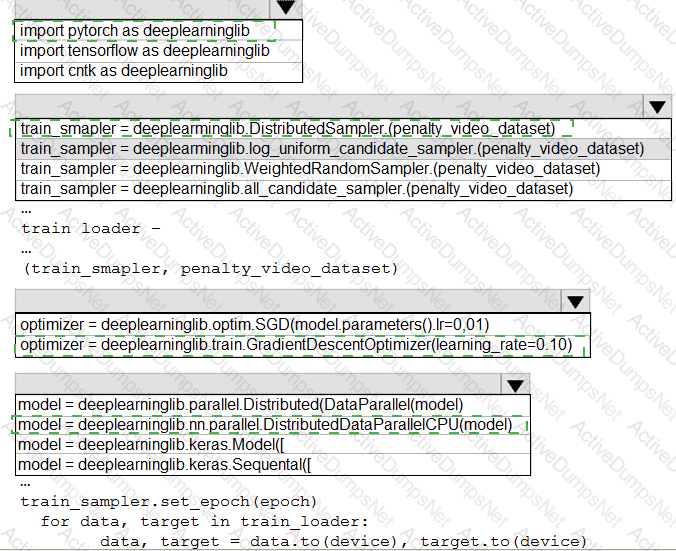
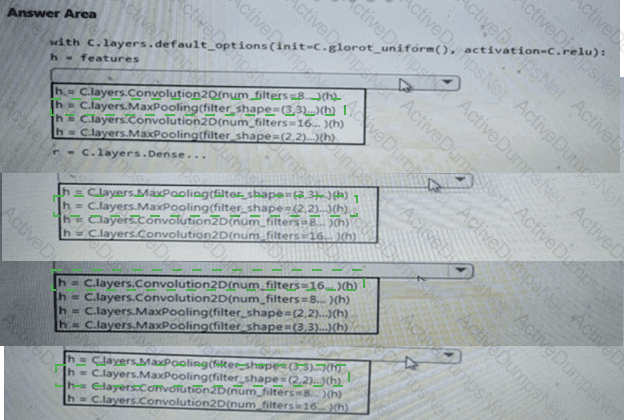
You need to use the Python language to build a sampling strategy for the global penalty detection models.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


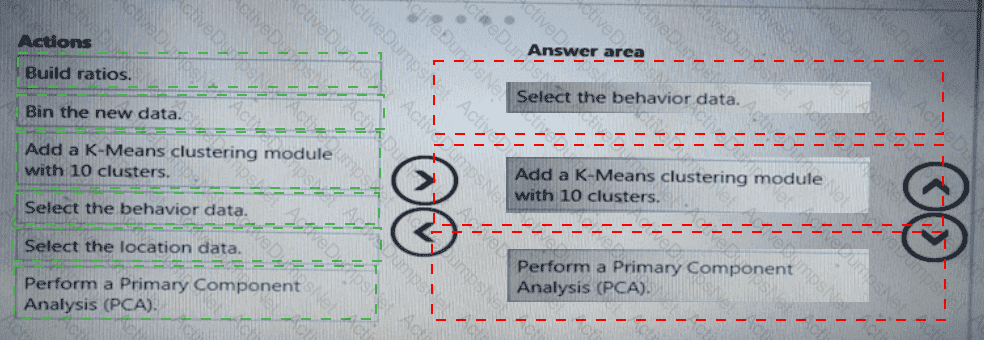
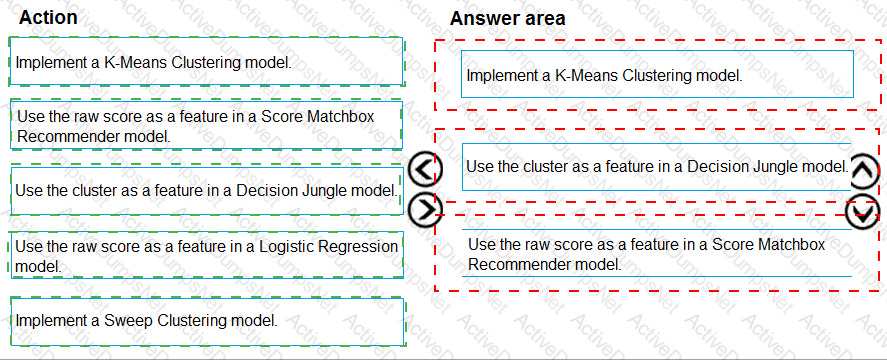
You need to modify the inputs for the global penalty event model to address the bias and variance issue.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

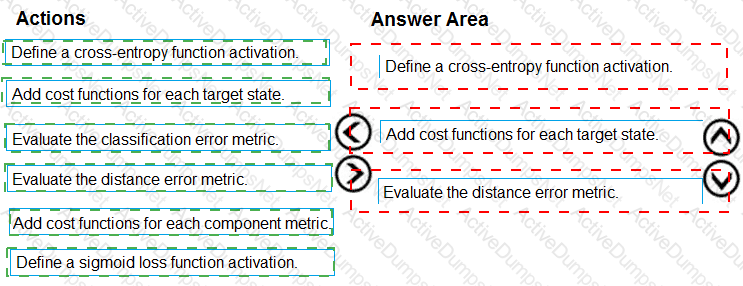
You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


You need to select an environment that will meet the business and data requirements.
Which environment should you use?
You need to implement a scaling strategy for the local penalty detection data.
Which normalization type should you use?
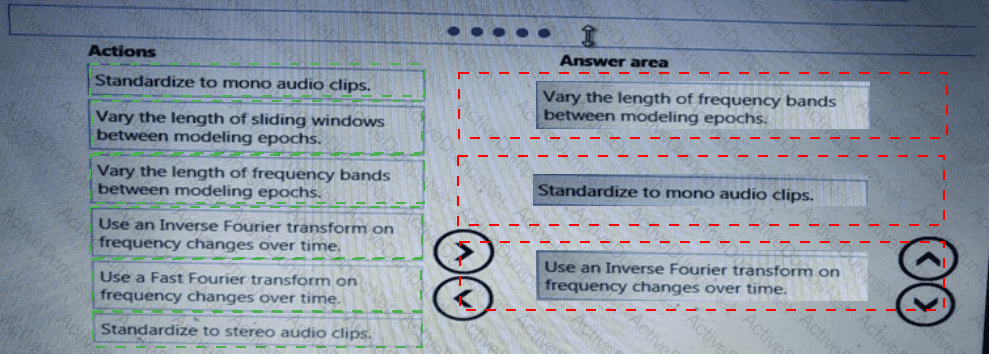
You need to implement a feature engineering strategy for the crowd sentiment local models.
What should you do?
You need to resolve the local machine learning pipeline performance issue. What should you do?
You need to build a feature extraction strategy for the local models.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You need to implement a new cost factor scenario for the ad response models as illustrated in the
performance curve exhibit.
Which technique should you use?

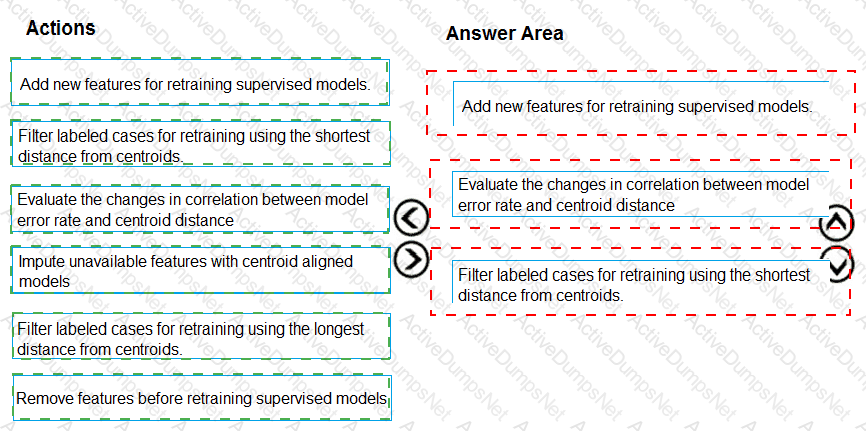
You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


You need to define a modeling strategy for ad response.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


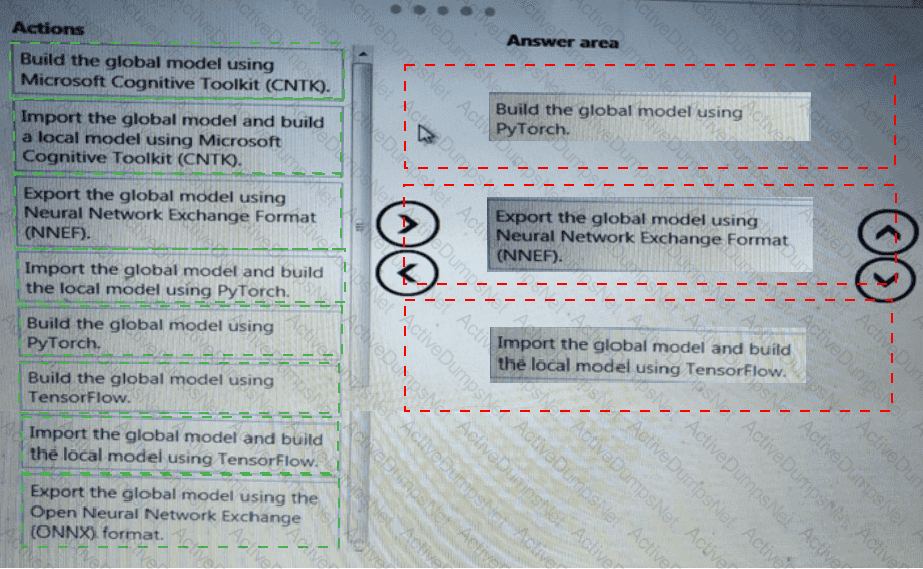
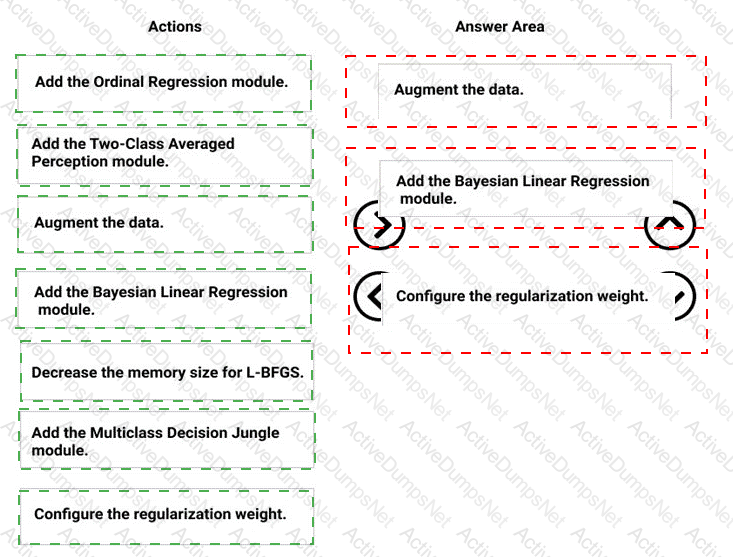
You need to define a process for penalty event detection.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

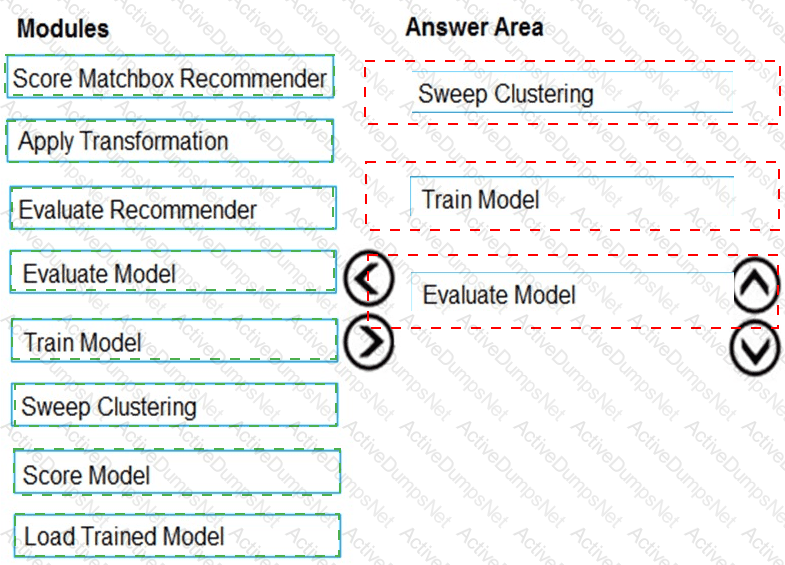
You need to produce a visualization for the diagnostic test evaluation according to the data visualization requirements.
Which three modules should you recommend be used in sequence? To answer, move the appropriate modules from the list of modules to the answer area and arrange them in the correct order.


You need to select a feature extraction method.
Which method should you use?
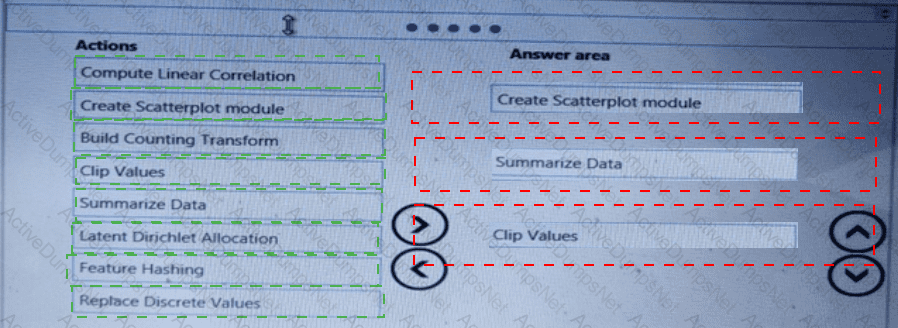
You need to visually identify whether outliers exist in the Age column and quantify the outliers before the outliers are removed.
Which three Azure Machine Learning Studio modules should you use in sequence? To answer, move the appropriate modules from the list of modules to the answer area and arrange them in the correct order.

You need to select a feature extraction method.
Which method should you use?
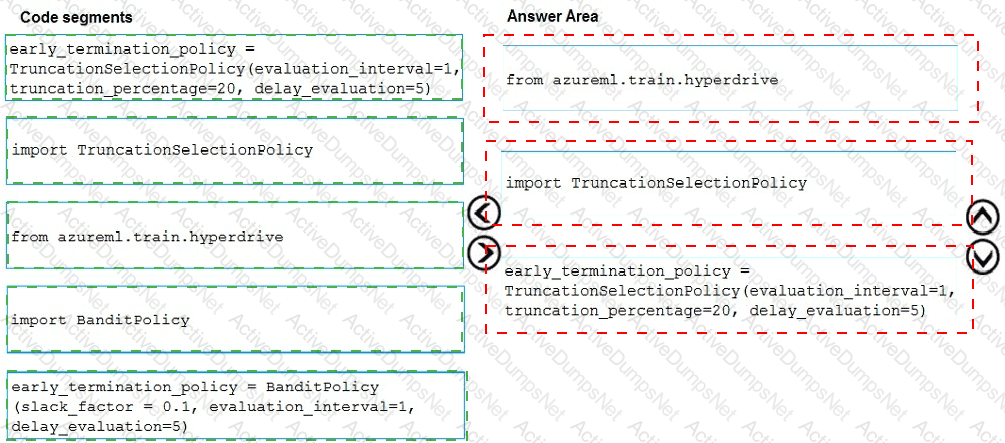
You need to implement early stopping criteria as suited in the model training requirements.
Which three code segments should you use to develop the solution? To answer, move the appropriate code segments from the list of code segments to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.


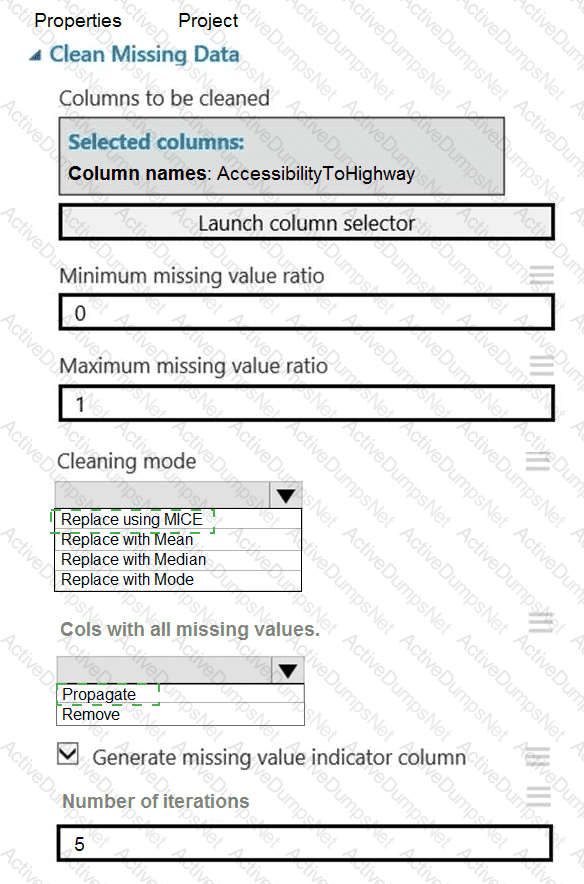
You need to replace the missing data in the AccessibilityToHighway columns.
How should you configure the Clean Missing Data module? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


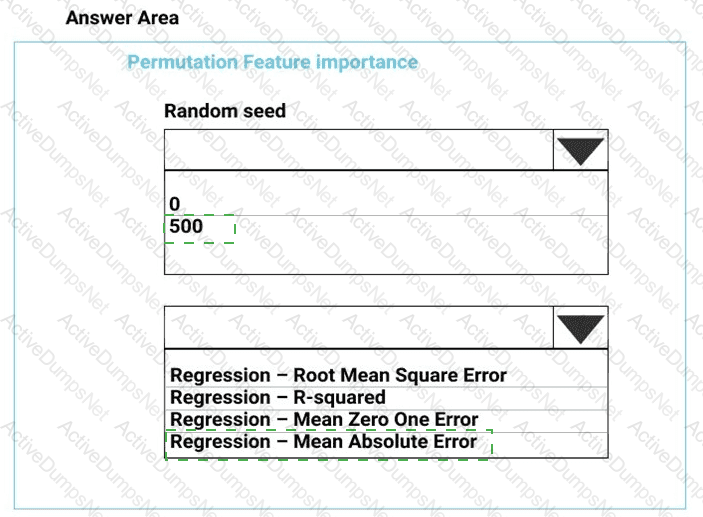
You need to set up the Permutation Feature Importance module according to the model training requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


You need to identify the methods for dividing the data according, to the testing requirements.
Which properties should you select? To answer, select the appropriate option-, m the answer area. NOTE: Each correct selection is worth one point.

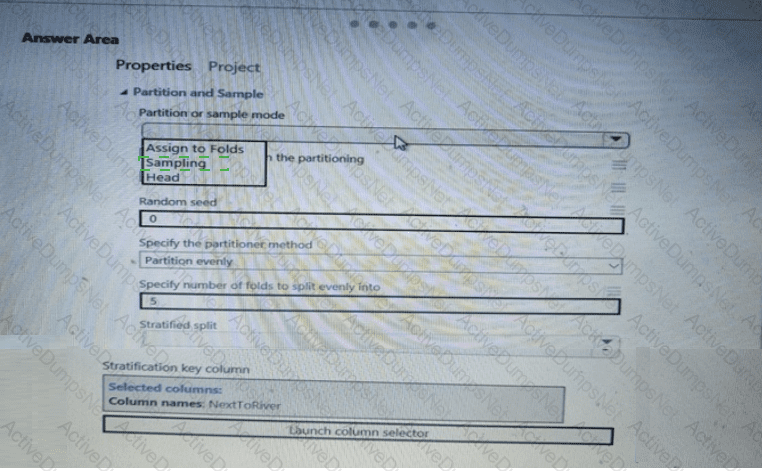
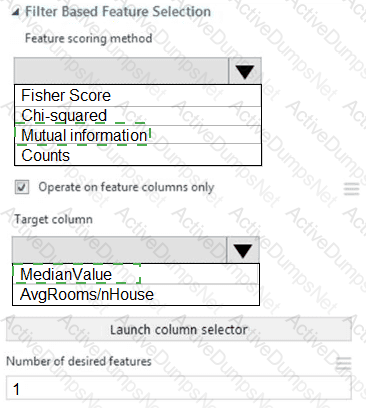
You need to configure the Feature Based Feature Selection module based on the experiment requirements and datasets.
How should you configure the module properties? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.


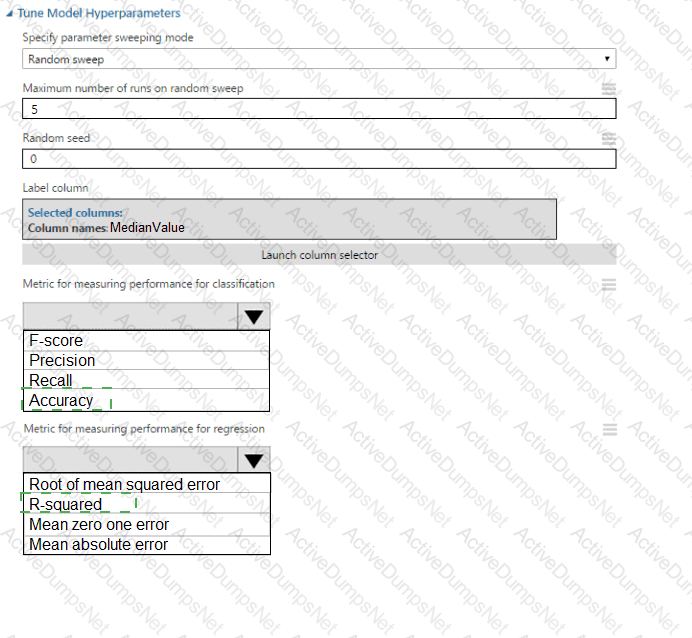
You need to identify the methods for dividing the data according to the testing requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.



You need to correct the model fit issue.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


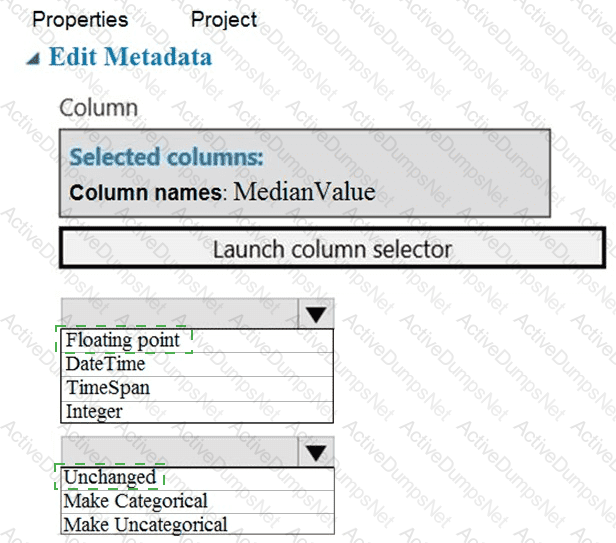
You need to configure the Edit Metadata module so that the structure of the datasets match.
Which configuration options should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


You need to configure the Permutation Feature Importance module for the model training requirements.
What should you do? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.


You ate reviewing model benchmarks in Azure Al Foundry.
You must use an embedding model that can assess rank-order relevance based on cosine similarity. You need to select the applicable embedding model. Which model metric should you focus on?
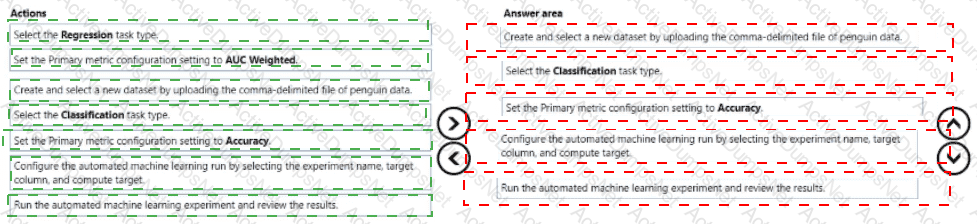
You are creating a machine learning model that can predict the species of a penguin from its measurements. You have a file that contains measurements for free species of penguin in comma delimited format.
The model must be optimized for area under the received operating characteristic curve performance metric averaged for each class.
You need to use the Automated Machine Learning user interface in Azure Machine Learning studio to run an experiment and find the best performing model.
Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the collect order.

You download a .csv file from a notebook in an Azure Machine Learning workspace to a data/sample.csv folder on a compute instance. The file contains 10,000 records. You must generate the summary statistics for the data in the file. The statistics must include the following for each numerical column:
• number of non-empty values
• average value
• standard deviation
• minimum and maximum values
• 25th. 50th. and 75th percentiles
You need to complete the Python code that will generate the summary statistics.
Which code segments should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


You manage an Azure Machine Learning workspace. The development environment tor managing the workspace is configured to use Python SDK v2 in Azure Machine Learning Notebooks A Synapse Spark Compute is currently attached and uses system-assigned identity You need to use Python code to update the Synapse Spark Compute 10 use a user-assigned identity.
Solution: Configure the IdentityConfiguration class with the appropriate identity type.
Does the solution meet the goal?
You use the Two-Class Neural Network module in Azure Machine Learning Studio to build a binary
classification model. You use the Tune Model Hyperparameters module to tune accuracy for the model.
You need to select the hyperparameters that should be tuned using the Tune Model Hyperparameters module.
Which two hyperparameters should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You deploy a real-time inference service for a trained model.
The deployed model supports a business-critical application, and it is important to be able to monitor the data submitted to the web service and the predictions the data generates.
You need to implement a monitoring solution for the deployed model using minimal administrative effort.
What should you do?

You manage an Azure Machine Learning workspace named workspace 1 and a Data Science Virtual Machine (DSVM) named DSMV1.
You must run an experiment on DSMV1 by using a Jupyter notebook and Python SDK v2 code. You must store metrics and artifacts in workspace1. You start by creating Python SDK v2 code to import all required packages.
You need to implement the Python SDK v2 code to store metrics and artifacts in workspace1.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
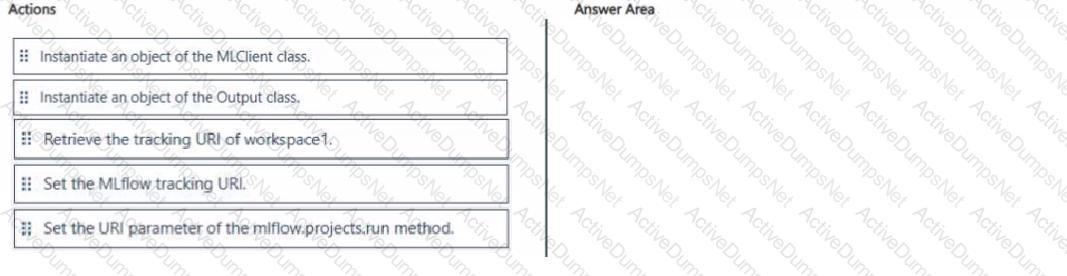
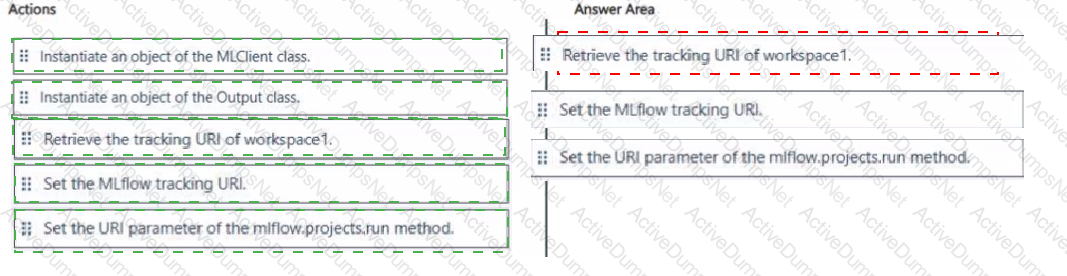
You have an Azure Machine Learning workspace named WS1.
You plan to use the Responsible Al dashboard to assess MLflow models that you will register in WS1.
You need to identify the library you should use to register the MLflow models.
Which library should you use?
You create an Azure Machine Learning workspace named workspaces. You create a Python SDK v2 notebook to perform custom model training in workspace1. You need to run the notebook from Azure Machine Learning Studio in workspace1. What should you provision first?
You manage an Azure Machine Learning workspace named workspace1 by using the Python SDK v2.
You must register datastores in workspace1 for Azure Blob and Azure Data Lake Gen2 storage to meet the following requirements:
• Data scientists accessing the datastore must have the same level of access.
• Access must be restricted to specified containers or folders.
You need to configure a security access method used to register the Azure Blob and Azure Data lake Gen? storage in workspace1. Which security access method should you configure? To answer, select the appropriate options in the answers area.
NOTE: Each correct selection is worth one point.


You previously deployed a model that was trained using a tabular dataset named training-dataset, which is based on a folder of CSV files.
Over time, you have collected the features and predicted labels generated by the model in a folder containing a CSV file for each month. You have created two tabular datasets based on the folder containing the inference data: one named predictions-dataset with a schema that matches the training data exactly, including the predicted label; and another named features-dataset with a schema containing all of the feature columns and a timestamp column based on the filename, which includes the day, month, and year.
You need to create a data drift monitor to identify any changing trends in the feature data since the model was trained. To accomplish this, you must define the required datasets for the data drift monitor.
Which datasets should you use to configure the data drift monitor? To answer, drag the appropriate datasets to the correct data drift monitor options. Each source may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.



You create a workspace to include a compute instance by using Azure Machine Learning Studio. You are developing a Python SDK v2 notebook in the workspace. You need to use Intellisense in the notebook. What should you do?
You create a deep learning model for image recognition on Azure Machine Learning service using GPU-based training.
You must deploy the model to a context that allows for real-time GPU-based inferencing.
You need to configure compute resources for model inferencing.
Which compute type should you use?
You create a workspace by using Azure Machine Learning Studio.
You must run a Python SDK v2 notebook in the workspace by using Azure Machine Learning Studio.
You need to reset the state of the notebook.
Which three actions should you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
You are solving a classification task.
You must evaluate your model on a limited data sample by using k-fold cross validation. You start by
configuring a k parameter as the number of splits.
You need to configure the k parameter for the cross-validation.
Which value should you use?
You use Azure Machine Learning Designer lo load the following datasets into an experiment:
Dataset1:

Dataset2:

You need to create a dataset that has the same columns and header row as the input datasets and contains all rows from both input datasets.
Solution: Use the Add Rows component.
Does the solution meet the goal?
: 214 HOTSPOT
You create a script for training a machine learning model in Azure Machine Learning service.
You create an estimator by running the following code:

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.



You create a binary classification model. The model is registered in an Azure Machine Learning workspace. You use the Azure Machine Learning Fairness SDK to assess the model fairness.
You develop a training script for the model on a local machine.
You need to load the model fairness metrics into Azure Machine Learning studio.
What should you do?
You manage an Azure AI Foundry project in your subscription. You deploy a gpt-4o model. You must test the model before you use it in an existing front-end application. You need to adjust the parameters to get more creative responses.
Solution: Increase Temperature.
Does the solution meet the goal?
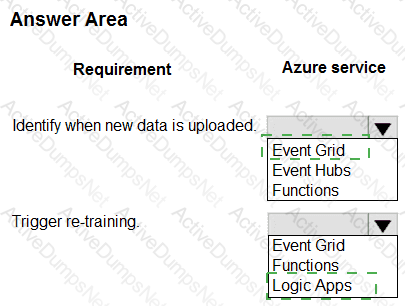
You train a model by using Azure Machine Learning. You use Azure Blob Storage to store production data.
The model must be re-trained when new data is uploaded to Azure Blob Storage. You need to minimize development and coding.
You need to configure Azure services to develop a re-training solution.
Which Azure services should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You create a multi-class image classification deep learning model that uses a set of labeled images. You
create a script file named train.py that uses the PyTorch 1.3 framework to train the model.
You must run the script by using an estimator. The code must not require any additional Python libraries to be installed in the environment for the estimator. The time required for model training must be minimized.
You need to define the estimator that will be used to run the script.
Which estimator type should you use?
You manage an Azure Machine Learning workspace. The development environment for managing the workspace is configured to use Python SDK v2 in Azure Machine Learning Notebooks.
A Synapse Spark Compute is currently attached and uses system-assigned identity.
You need to use Python code to update the Synapse Spark Compute to use a user-assigned identity.
Solution: Initialize the DefaultAzureCredential class.
Does the solution meet the goal?

You must use the Azure Machine Learning SDK to interact with data and experiments in the workspace.
You need to configure the config.json file to connect to the workspace from the Python environment.
Which two additional parameters must you add to the config.json file in order to connect to the workspace? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
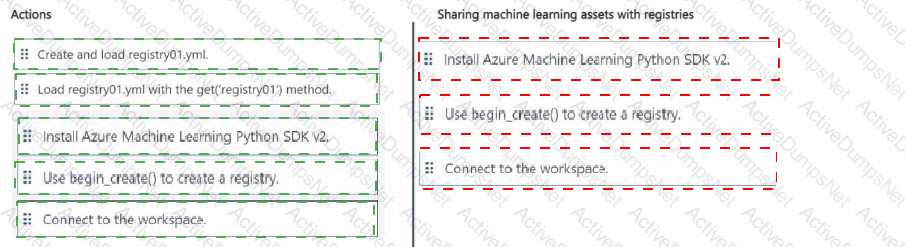
You manage an Azure Machine Learning workspace named workspaces
You plan to create a registry named registry01 with the help of the following registry.yml (line numbers are used for reference only):

You need to use Azure Machine Learning Python SDK v2 with Python 3.10 in a notebook to interact with workspace1.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

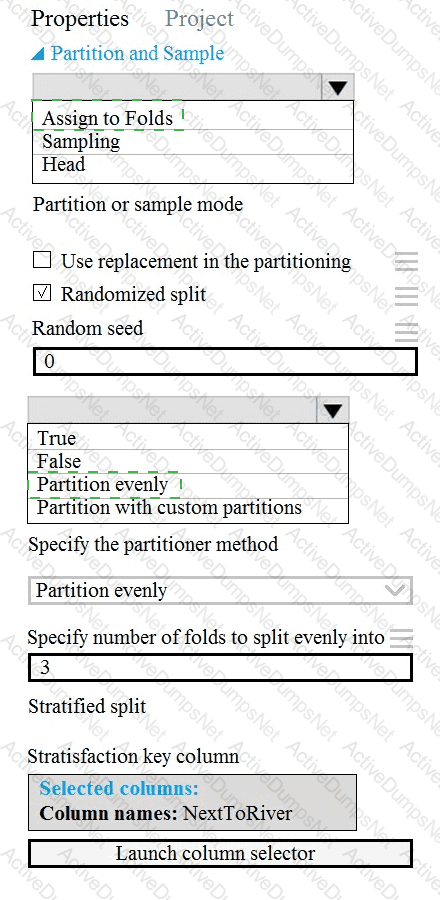
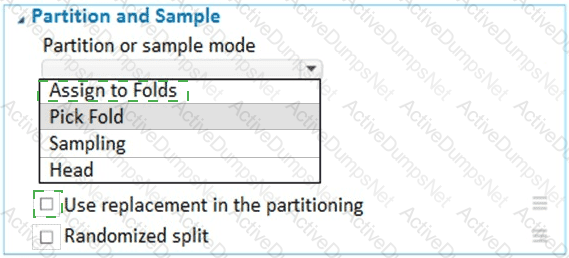
You have a dataset that contains 2,000 rows. You are building a machine learning classification model by using Azure Learning Studio. You add a Partition and Sample module to the experiment.
You need to configure the module. You must meet the following requirements:
Divide the data into subsets
Assign the rows into folds using a round-robin method
Allow rows in the dataset to be reused
How should you configure the module? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.


You are analyzing a raw dataset that requires cleaning.
You must perform transformations and manipulations by using Azure Machine Learning Studio.
You need to identify the correct modules to perform the transformations.
Which modules should you choose? To answer, drag the appropriate modules to the correct scenarios. Each module may be used once, more than once, or not at all.
You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.


