Microsoft AI-102 Designing and Implementing a Microsoft Azure AI Solution Exam Practice Test
Designing and Implementing a Microsoft Azure AI Solution Questions and Answers
You have an Azure Al agent solution.
You plan to create an agent-based app named App1 that will analyze and summarize data for users and generate data-driven recommendations. App1 will be used by non-technical business users and must adapt to new and unforeseen business challenges and improve its performance over time.
You need to identify which type of agent to use in App1. The solution must meet the following requirements:
• Adapt and improve the agents ' performance over time based on user feedback.
• Provide tailored recommendations to help users make informed decisions.
• Provide the best possible performance of the app.
Which agent type should you identify?
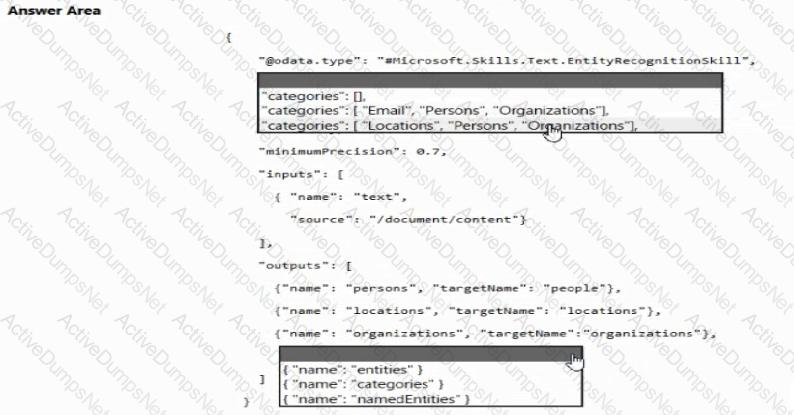
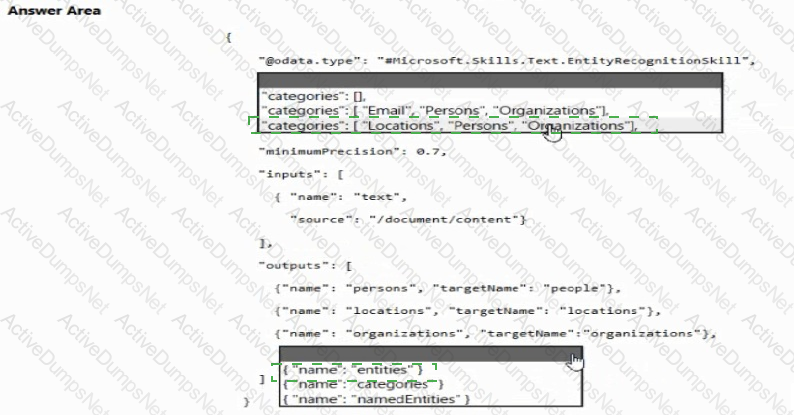
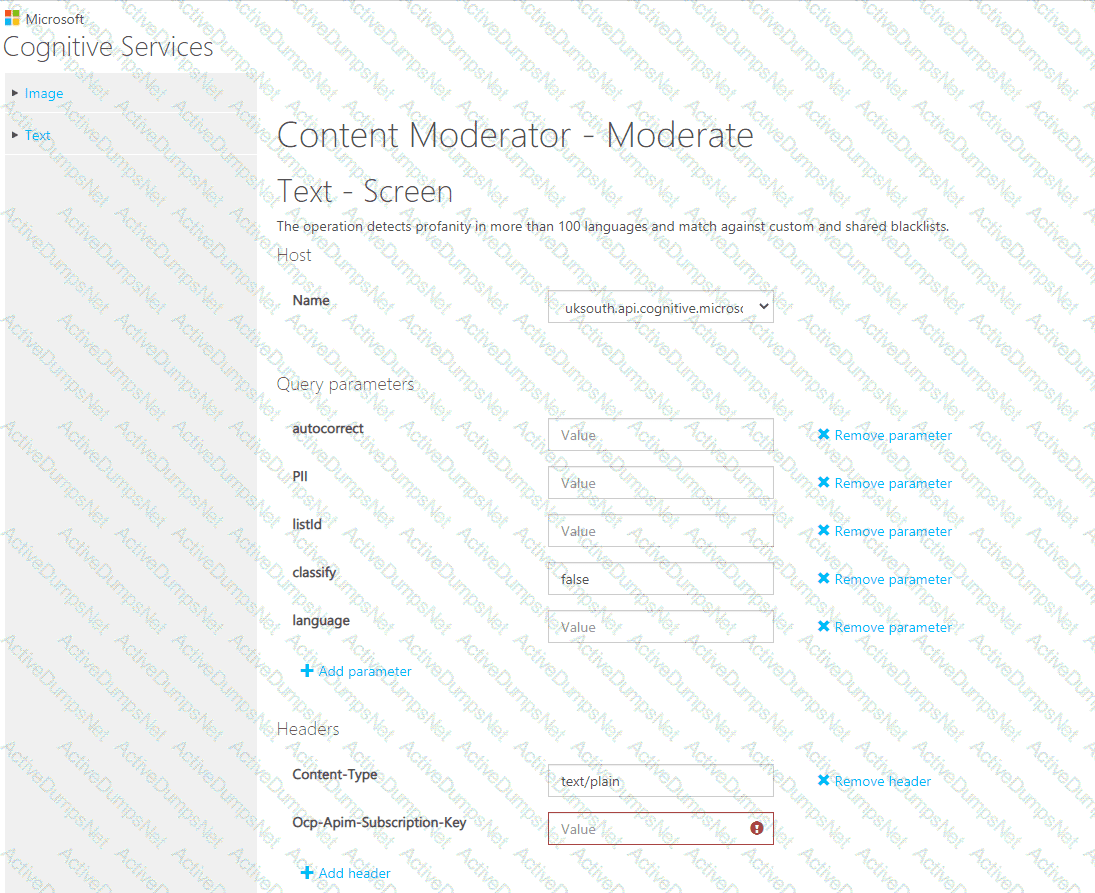
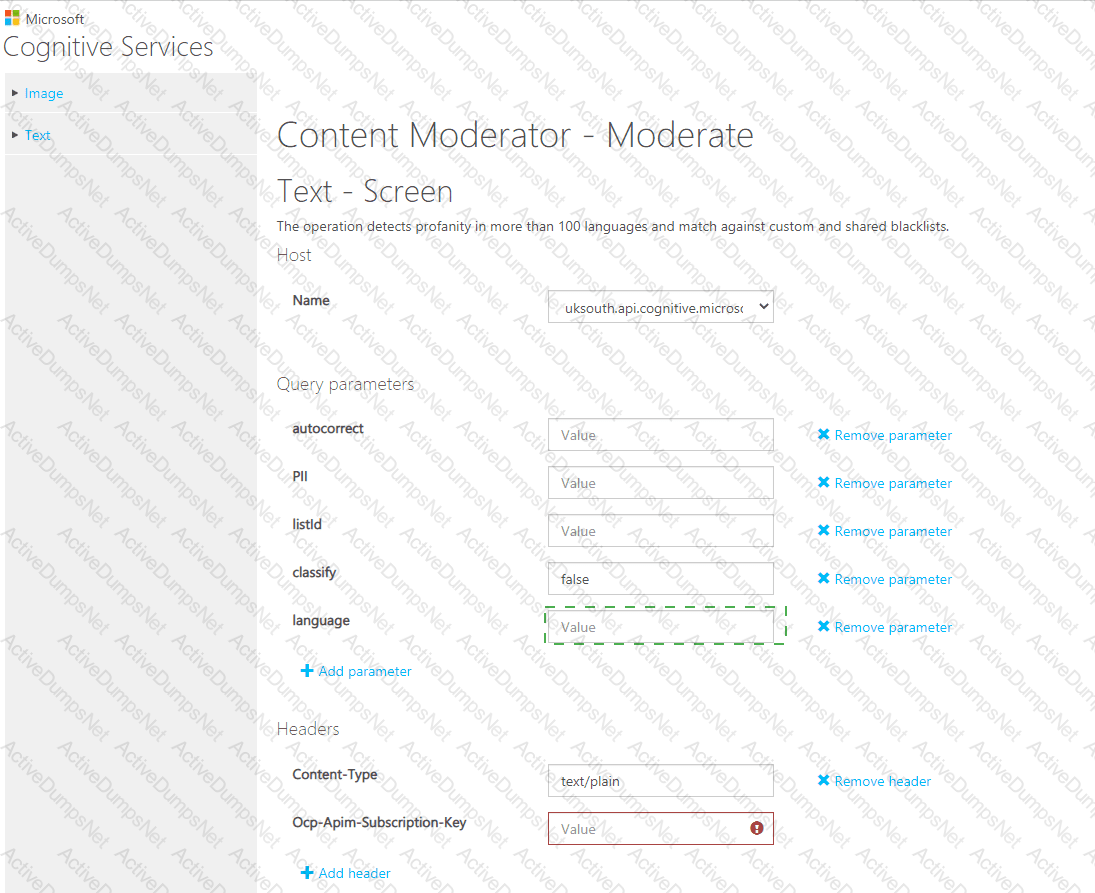
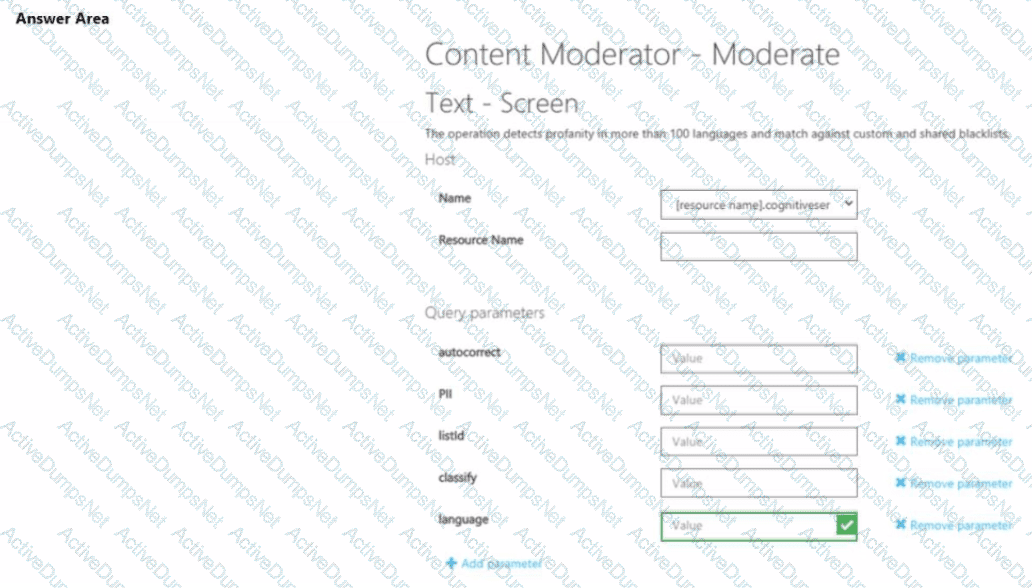
You are building a chatbot.
You need to use the Content Moderator API to identify aggressive and sexually explicit language.
Which three settings should you configure? To answer, select the appropriate settings in the answer area.
NOTE: Each correct selection is worth one point.
You have a product knowledgebase that contains multiple PDF documents.
You need to build a chatbot that will provide responses based on data in the knowledgebase. The solution must minimize development effort and costs.
What should you include in the solution?
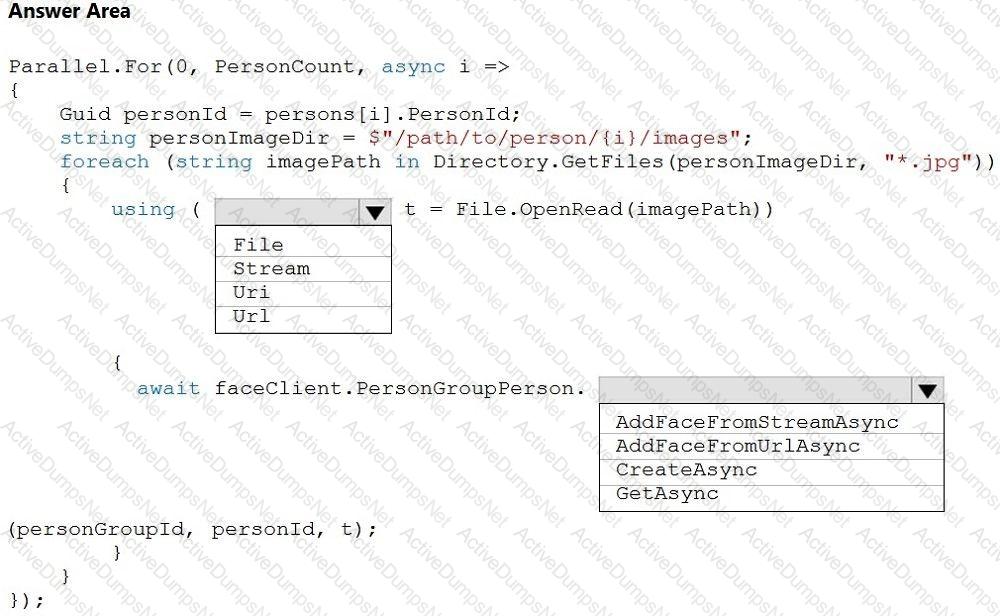
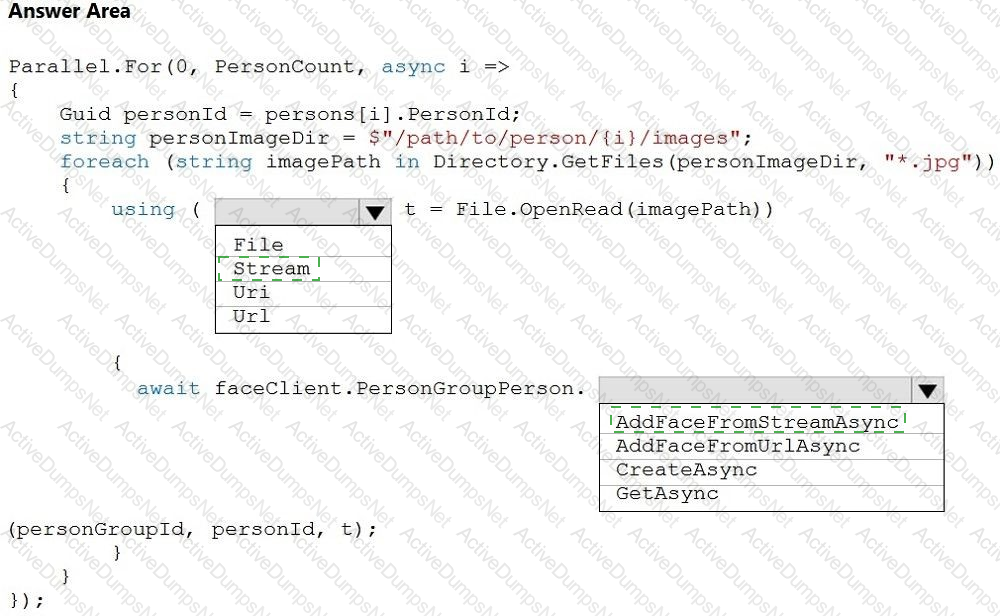
You develop an application that uses the Face API.
You need to add multiple images to a person group.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You are building an image sharing app that will use Azure AI to prevent users from sharing sexually explicit images.
You need to ensure that inappropriate images are identified correctly. The solution must minimize development effort.
What should you use?
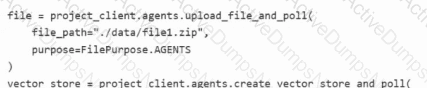
You are building an agent by using the Azure Al Foundry Agent Service.
You have the following code.

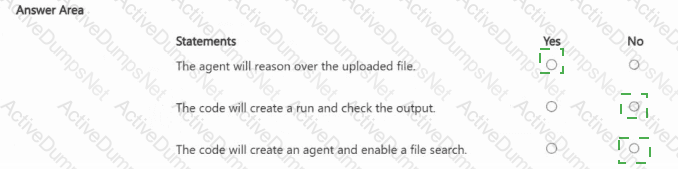
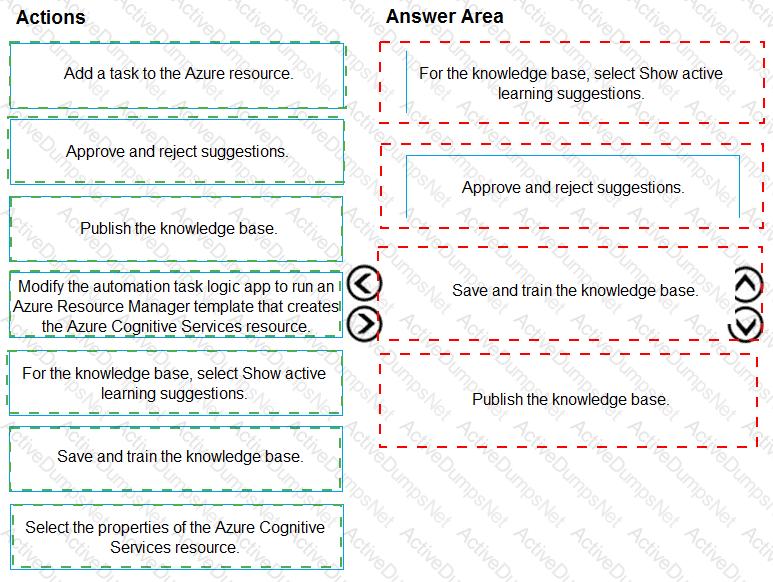
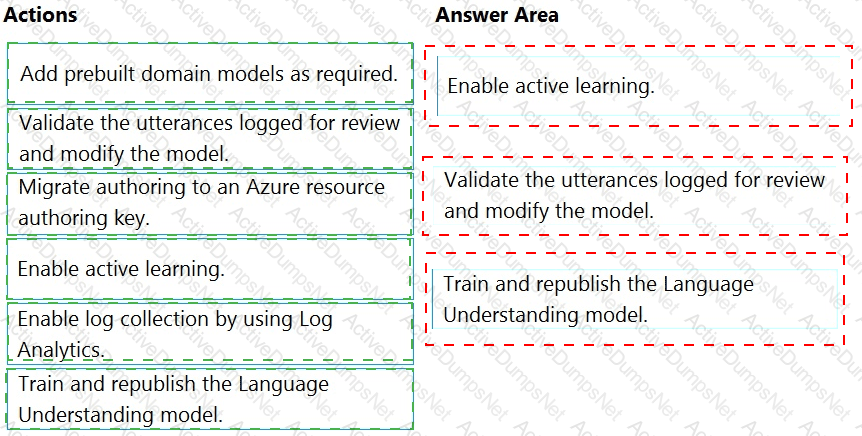
You have a chatbot that uses a QnA Maker application.
You enable active learning for the knowledge base used by the QnA Maker application.
You need to integrate user input into the model.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


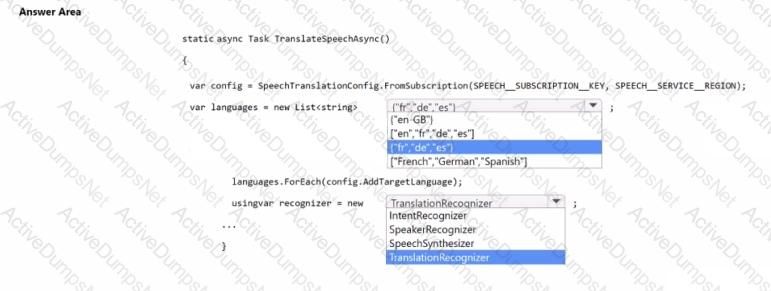
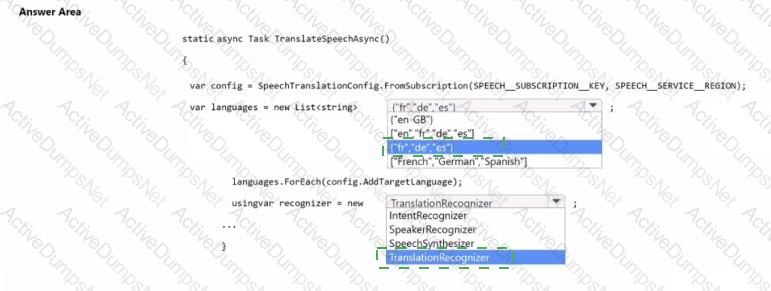
You are building an app that will automatically translate speech from English to French, German, and Spanish by using Azure Al service.
You need to define the output languages and configure the Azure Al Speech service.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You have a computer that contains the files shown in the following table.
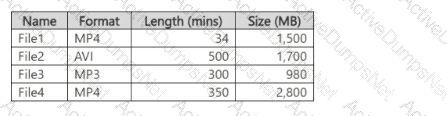
Which files can you upload and analyze by using Azure Al Video Indexer?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a chatbot that uses question answering in Azure Cognitive Service for Language
Users report that the responses of the chatbot lark formality when answering spurious questions
You need to ensure that the chatbot provides formal responses to spurious questions.
Solution: From Language Studio, you change the chitchat source to qna_chitchit_friindly.tsv. and then retrain and republish the model.
Does this meet the goal?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a chatbot that uses question answering in Azure Cognitive Service for Language
Users report that the responses of the chatbot lark formality when answering spurious questions
You need to ensure that the chatbot provides formal responses to spurious questions.
Solution: From Language Studio, you remove all the chit-chat question and answer pairs, and then retrain and republish the model
Does this meet the goal?
You are developing a solution to generate a word cloud based on the reviews of a company’s products.
Which Text Analytics REST API endpoint should you use?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a chatbot that uses question answering in Azure Cognitive Service for Language.
Users report that the responses of the chatbot lack formality when answering random questions that are outside the scope of the knowledge base.
You need to ensure that the chatbot provides formal responses to these spurious questions.
Solution: From Language Studio, you modify the question and answer pairs for the custom intents, and then retrain and republish the model.
Does this meet the goal?
You are building a multilingual chatbot.
You need to send a different answer for positive and negative messages.
Which two Text Analytics APIs should you use? Each correct answer presents part of the solution. (Choose two.)
NOTE: Each correct selection is worth one point.
You are building an app that will use the Azure AI Speech service.
You need to ensure that the app can authenticate to the service by using a Microsoft Entra ID token.
Which two action should you perform? Each answer part of the solution.
NOTE: Each correct selection is worth one point.
Your company has a repotting solution that has paginated reports. The reports query a dimensional model in a data warehouse. Which type of processing does the reporting solution use?
You have an Azure subscription.
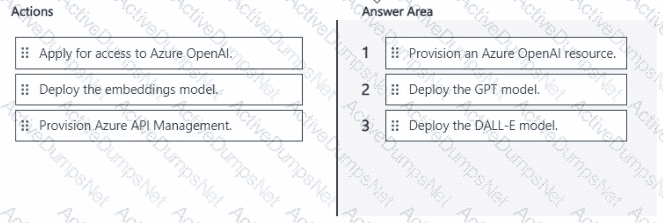
You are building a chatbot that will use an Azure OpenAI model.
You need to deploy the model.
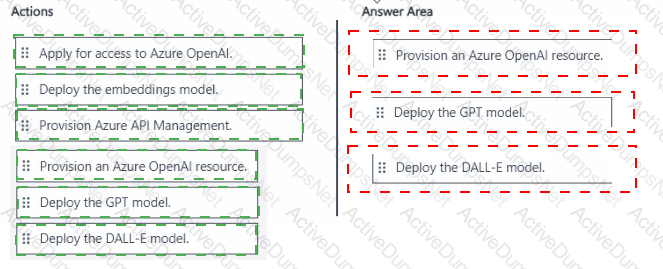
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
You are building an agent by using the Microsoft Foundry Agent Service.
You need to ensure that the agent can access publicly accessible data that was released during the past 90 days.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


You have an Azure loT hub that receives series data from machinery. You need to build an app that will perform the following actions:
• Perform anomaly detection across multiple correlated sensors
• Identify the root cause of process stops.
• Send incident alerts
The solution must minimize development time. Which Azure service should you use?
You need to upload speech samples to a Speech Studio project. How should you upload the samples?
You have a custom agent named Agent1.
You need to control access to and monitor activity for Agent1 by using Microsoft Foundry.
What should you do first?
You need to store event log data that is semi-structured and received as the logs occur. What should you use?
You have a library that contains 1,000 video files.
You need to perform sentiment analysis on the videos by using an Azure Al Content Understanding project. The solution must minimize development effort.
Which type of template should you use for the project?
You build a language model by using Conversational Language Understanding. The language model is used to search for information on a contact list by using an intent named Findcontact. A conversational expert provides you with the following list of phrases to use for training
• Find contacts in London.
• Who do I know in Seattle?
• Search for contacts m Ukraine.
You need to implement the phrase list in Conversational Language Understanding.
Solution: You create a new utterance for each phrase in the FindContact intent.
What is a primary characteristic of a relational database?
You need to analyze video content to identify any mentions of specific company names.
Which three actions should you perform in sequence? To answer move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.



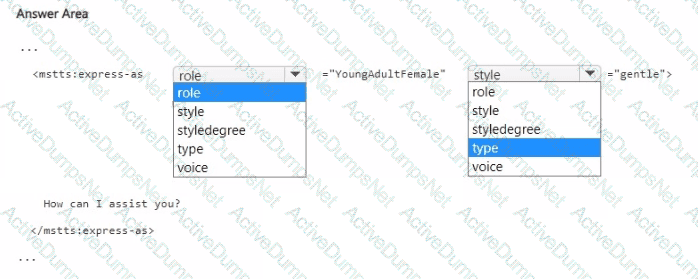
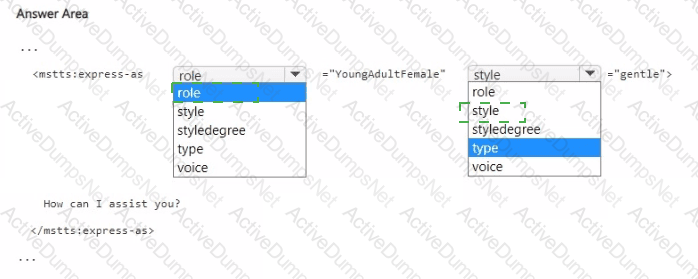
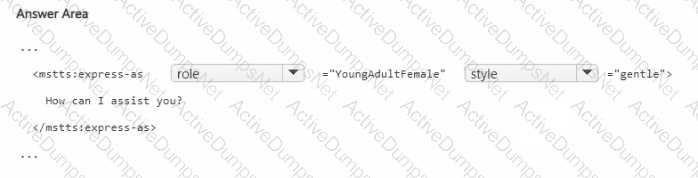
You are building a text-to-speech app that will use a custom neural voice.
You need to create an SSML file for the app. The solution must ensure that the voice profile meets the following requirements:
• Expresses a calm tone
• Imitates the voice of a young adult female
How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
You have a factory that produces cardboard packaging for food products. The factory has intermittent internet connectivity.
The packages are required to include four samples of each product.
You need to build a Custom Vision model that will identify defects in packaging and provide the location of the defects to an operator. The model must ensure that each package contains the four products.
Which project type and domain should you use? To answer, drag the appropriate options to the correct targets. Each option may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content
NOTE: Each correct selection is worth one point.


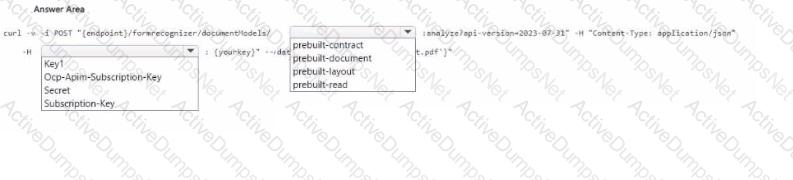
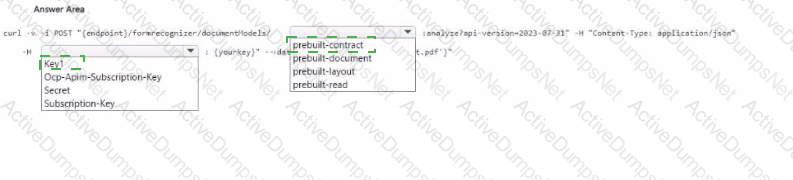
You have receipts that are accessible from a URL.
You need to extract data from the receipts by using Form Recognizer and the SDK. The solution must use a prebuilt model.
Which client and method should you use?
You deploy a web app that is used as a management portal for indexing in Azure Cognitive Search. The app is configured to use the primary admin key.
During a security review, you discover unauthorized changes to the search index. You suspect that the primary access key is compromised.
You need to prevent unauthorized access to the index management endpoint. The solution must minimize downtime.
What should you do next?
You have a custom Azure OpenAI model.
You have the files shown in the following table.
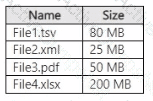
You need to prepare training data for the model by using the OpenAI CLI data preparation tool. Which files can you upload to the tool?
Select the answer that correctly completes the sentence.



You are building a language model by using a Language Understanding service.
You create a new Language Understanding resource.
You need to add more contributors.
What should you use?
You are building a solution in Azure that will use Azure AI Language service to process sensitive customer data.
You need to ensure that only specific Azure processes can access the Language service. The solution must minimize administrative.
What should you include in the solution?
For each of the following statements, select Yes if the statement is tine. Otherwise, select No. NOTE: Each correct selection is worth one point.


You are using a Language Understanding service to handle natural language input from the users of a web-based customer agent.
The users report that the agent frequently responds with the following generic response: " Sorry, I don ' t understand that. "
You need to improve the ability of the agent to respond to requests.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. (Choose three.)

You need to measure the public perception of your brand on social media by using natural language processing. Which Azure service should you use?
You have an Azure subscription that contains an Azure AI Document intelligence resource named D1.
You create a PDF document named test.pdf that contain tabular data.
You need to analyze Test.pdf by using DI1.
How should you complete the command? To answer, select the appropriate option in the answer area.
NOTE: Each correct selection is worth one point.

What are two benefits of platform as a service (PaaS) relational database offerings in Azure, such as Azure SQL Database? Each correct answer presents a complete solution.
NOTE: Each correct selection Is worth one point.
You plan to use a Conversational Language Understanding application named app1 that is deployed to a container. App1 was developed by using a Conversational Language Understanding authoring resource named Iu1. App1 has the versions shown in the following table.

You need to create a container that uses the latest deployable version of app1.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


You have a video recording of a company meeting that includes presentations by multiple presenters.
You plan to use Azure AI Video Indexer to process the video and generate a separate text file for each presenter ' s presentation.
You need to identify each presenter in the video and attribute each text file to a presenter.
Which insight should you extract?
You ace developing an app that will use the Speech and language APIs.
You need to provision resources for the app. The solution must ensure that each service is accessed by using a single endpoint and credential
Which type of resource should you create?
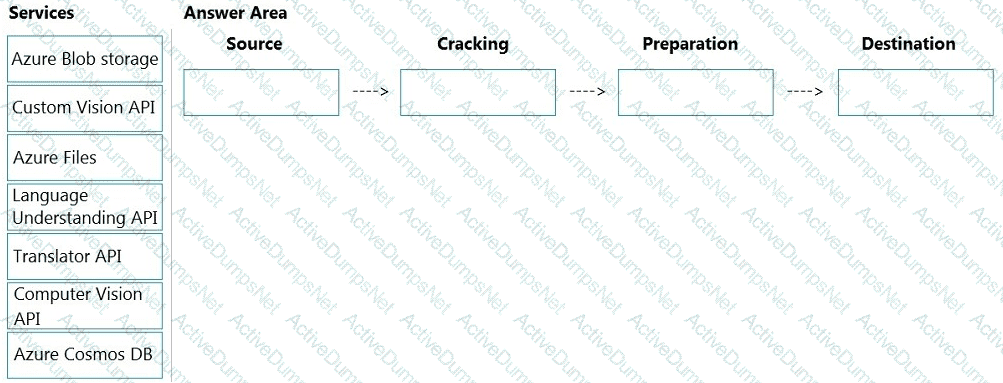
You are developing the smart e-commerce project.
You need to design the skillset to include the contents of PDFs in searches.
How should you complete the skillset design diagram? To answer, drag the appropriate services to the correct stages. Each service may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
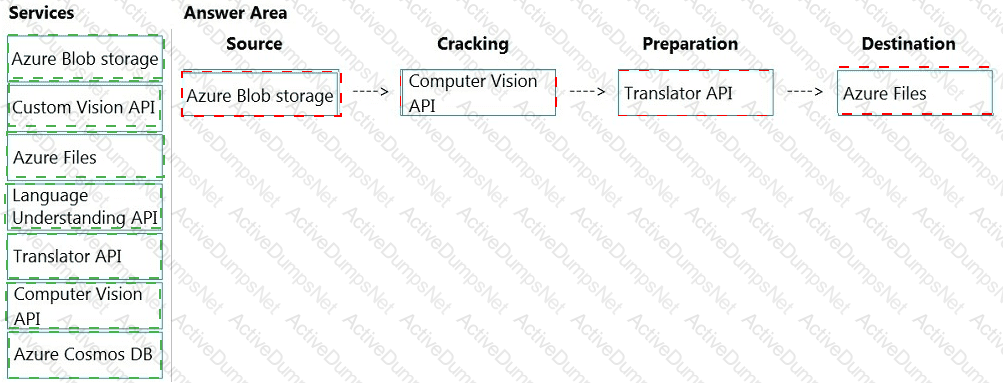

You are developing the smart e-commerce project.
You need to implement autocompletion as part of the Cognitive Search solution.
Which three actions should you perform? Each correct answer presents part of the solution. (Choose three.)
NOTE: Each correct selection is worth one point.
You are planning the product creation project.
You need to recommend a process for analyzing videos.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. (Choose four.)



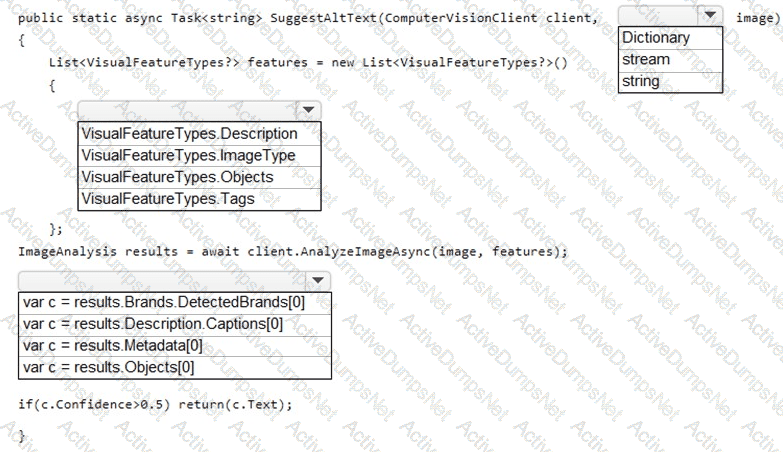
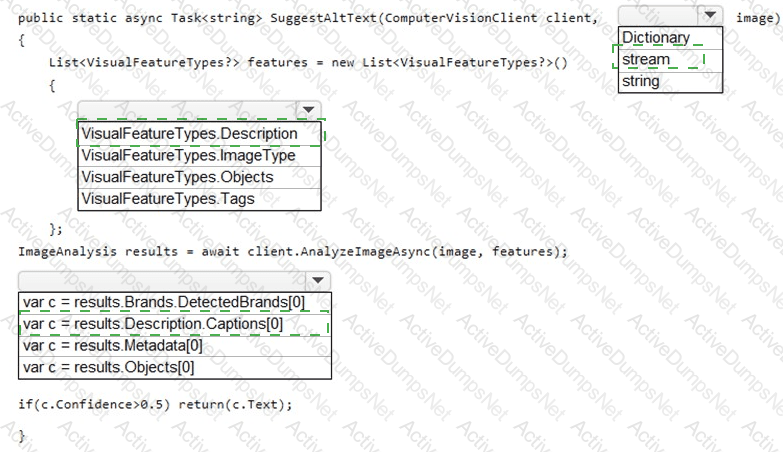
You need to develop code to upload images for the product creation project. The solution must meet the accessibility requirements.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
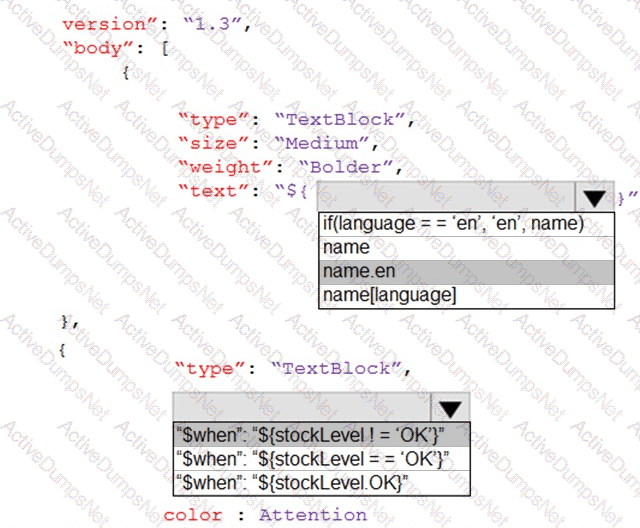
You are developing the shopping on-the-go project.
You need to build the Adaptive Card for the chatbot.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


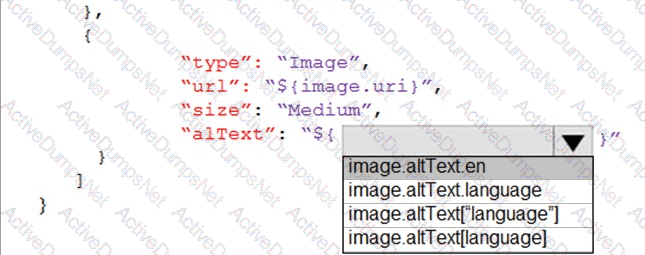
You are developing the shopping on-the-go project.
You are configuring access to the QnA Maker resources.
Which role should you assign to AllUsers and LeadershipTeam? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


You are planning the product creation project.
You need to build the REST endpoint to create the multilingual product descriptions.
How should you complete the URI? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


You are developing the document processing workflow.
You need to identify which API endpoints to use to extract text from the financial documents. The solution must meet the document processing requirements.
Which two API endpoints should you identify? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You are developing the chatbot.
You create the following components:
* A QnA Maker resource
* A chatbot by using the Azure Bot Framework SDK.
You need to integrate the components to meet the chatbot requirements.
Which property should you use?
You need to develop an extract solution for the receipt images. The solution must meet the document processing requirements and the technical requirements.
You upload the receipt images to the From Recognizer API for analysis, and the API ret urns the following JSON.

Which expression should you use to trigger a manual review of the extracted information by a member of the Consultant-Bookkeeper group?
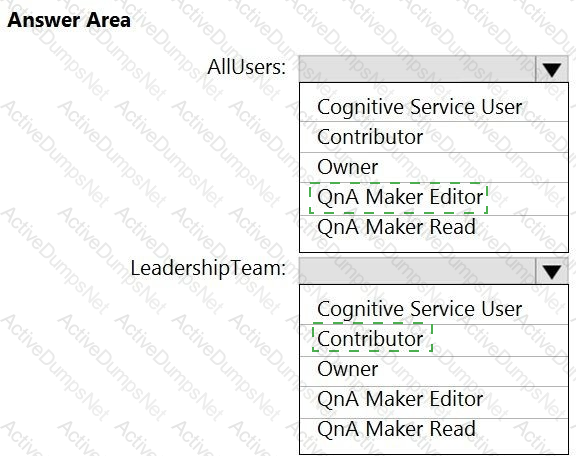
You build a QnA Maker resource to meet the chatbot requirements.
Which RBAC role should you assign to each group? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
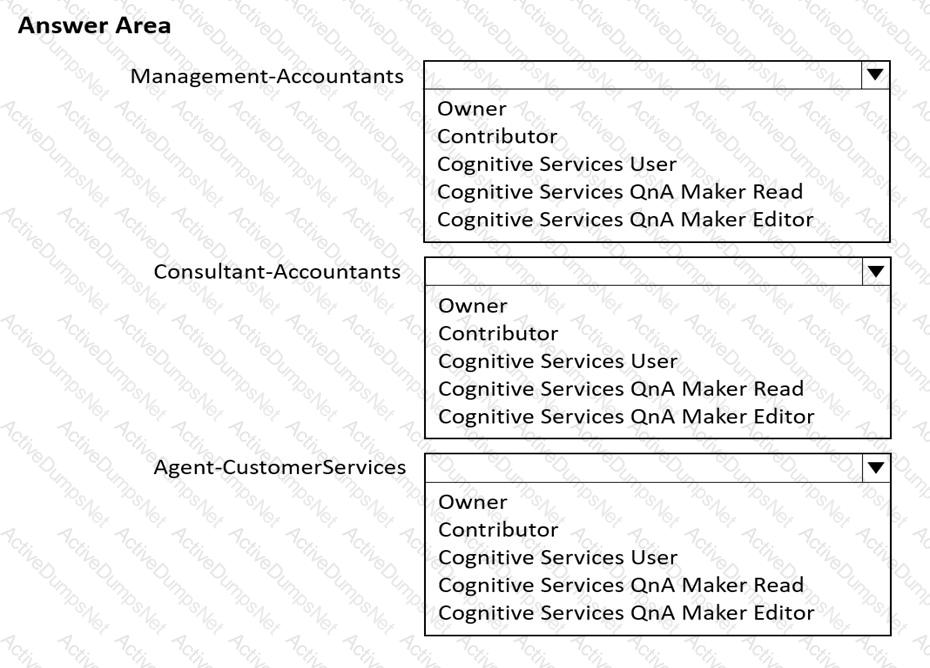

You are developing a solution for the Management-Bookkeepers group to meet the document processing requirements. The solution must contain the following components:
A form Recognizer resource
An Azure web app that hosts the Form Recognizer sample labeling tool
The Management-Bookkeepers group needs to create a custom table extractor by using the sample labeling tool.
Which three actions should the Management-Bookkeepers group perform in sequence? To answer, move the appropriate cmdlets from the list of cmdlets to the answer area and arrange them in the correct order.
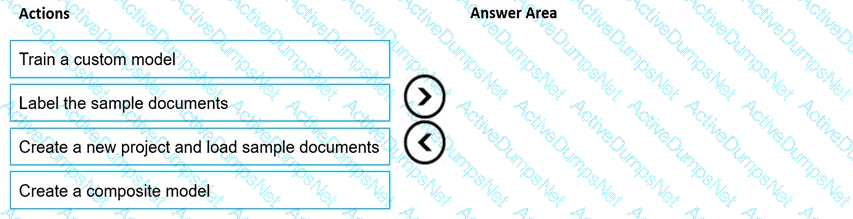
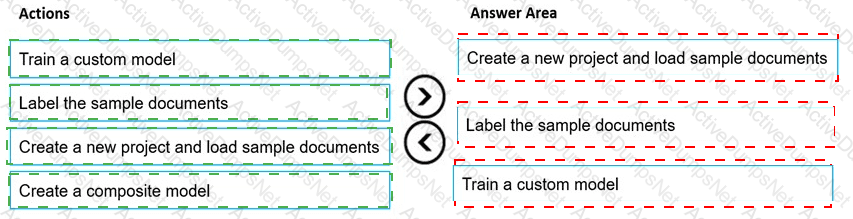
You are developing the knowledgebase.
You use Azure Video Analyzer for Media (previously Video indexer) to obtain transcripts of webinars.
You need to ensure that the solution meets the knowledgebase requirements.
What should you do?
You are developing the chatbot.
You create the following components:
• A QnA Maker resource
• A chatbot by using the Azure Bot Framework SDK
You need to add an additional component to meet the technical requirements and the chatbot requirements. What should you add?
You are developing the knowledgebase by using Azure Cognitive Search.
You need to meet the knowledgebase requirements for searching equivalent terms.
What should you include in the solution?
You are developing the knowledgebase by using Azure Cognitive Search.
You need to process wiki content to meet the technical requirements.
What should you include in the solution?
You are developing the knowledgebase by using Azure Cognitive Search.
You need to build a skill that will be used by indexers.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.