A data scientist is utilizing MLflow Autologging to automatically track their machine learning experiments. After completing a series of runs for the experiment experiment_id, the data scientist wants to identify the run_id of the run with the best root-mean-square error (RMSE).
Which of the following lines of code can be used to identify the run_id of the run with the best RMSE in experiment_id?
A)

B)

C)
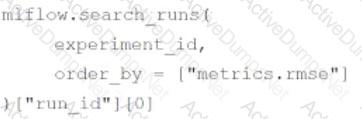
D)

A data scientist learned during their training to always use 5-fold cross-validation in their model development workflow. A colleague suggests that there are cases where a train-validation split could be preferred over k-fold cross-validation when k > 2.
Which of the following describes a potential benefit of using a train-validation split over k-fold cross-validation in this scenario?
A data scientist has developed a machine learning pipeline with a static input data set using Spark ML, but the pipeline is taking too long to process. They increase the number of workers in the cluster to get the pipeline to run more efficiently. They notice that the number of rows in the training set after reconfiguring the cluster is different from the number of rows in the training set prior to reconfiguring the cluster.
Which of the following approaches will guarantee a reproducible training and test set for each model?
A data scientist wants to efficiently tune the hyperparameters of a scikit-learn model. They elect to use the Hyperopt library'sfminoperation to facilitate this process. Unfortunately, the final model is not very accurate. The data scientist suspects that there is an issue with theobjective_functionbeing passed as an argument tofmin.
They use the following code block to create theobjective_function:

Which of the following changes does the data scientist need to make to theirobjective_functionin order to produce a more accurate model?
Which of the Spark operations can be used to randomly split a Spark DataFrame into a training DataFrame and a test DataFrame for downstream use?
A team is developing guidelines on when to use various evaluation metrics for classification problems. The team needs to provide input on when to use the F1 score over accuracy.
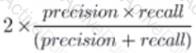
Which of the following suggestions should the team include in their guidelines?
A data scientist is working with a feature set with the following schema:

Thecustomer_idcolumn is the primary key in the feature set. Each of the columns in the feature set has missing values. They want to replace the missing values by imputing a common value for each feature.
Which of the following lists all of the columns in the feature set that need to be imputed using the most common value of the column?
A data scientist wants to tune a set of hyperparameters for a machine learning model. They have wrapped a Spark ML model in the objective functionobjective_functionand they have defined the search spacesearch_space.
As a result, they have the following code block:

Which of the following changes do they need to make to the above code block in order to accomplish the task?
A machine learning engineer would like to develop a linear regression model with Spark ML to predict the price of a hotel room. They are using the Spark DataFrametrain_dfto train the model.
The Spark DataFrametrain_dfhas the following schema:

The machine learning engineer shares the following code block:
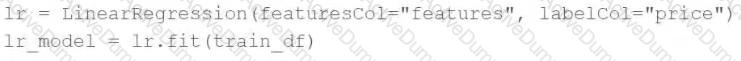
Which of the following changes does the machine learning engineer need to make to complete the task?
The implementation of linear regression in Spark ML first attempts to solve the linear regression problem using matrix decomposition, but this method does not scale well to large datasets with a large number of variables.
Which of the following approaches does Spark ML use to distribute the training of a linear regression model for large data?
A data scientist is wanting to explore summary statistics for Spark DataFrame spark_df. The data scientist wants to see the count, mean, standard deviation, minimum, maximum, and interquartile range (IQR) for each numerical feature.
Which of the following lines of code can the data scientist run to accomplish the task?
A machine learning engineer is trying to scale a machine learning pipeline by distributing its single-node model tuning process. After broadcasting the entire training data onto each core, each core in the cluster can train one model at a time. Because the tuning process is still running slowly, the engineer wants to increase the level of parallelism from 4 cores to 8 cores to speed up the tuning process. Unfortunately, the total memory in the cluster cannot be increased.
In which of the following scenarios will increasing the level of parallelism from 4 to 8 speed up the tuning process?
A data scientist has developed a random forest regressor rfr and included it as the final stage in a Spark MLPipeline pipeline. They then set up a cross-validation process with pipeline as the estimator in the following code block:

Which of the following is a negative consequence of includingpipelineas the estimator in the cross-validation process rather thanrfras the estimator?
An organization is developing a feature repository and is electing to one-hot encode all categorical feature variables. A data scientist suggests that the categorical feature variables should not be one-hot encoded within the feature repository.
Which of the following explanations justifies this suggestion?
A data scientist has a Spark DataFrame spark_df. They want to create a new Spark DataFrame that contains only the rows from spark_df where the value in column price is greater than 0.
Which of the following code blocks will accomplish this task?
The implementation of linear regression in Spark ML first attempts to solve the linear regression problem using matrix decomposition, but this method does not scale well to large datasets with a large number of variables.
Which of the following approaches does Spark ML use to distribute the training of a linear regression model for large data?
Which of the following statements describes a Spark ML estimator?
A data scientist wants to use Spark ML to one-hot encode the categorical features in their PySpark DataFramefeatures_df. A list of the names of the string columns is assigned to theinput_columnsvariable.
They have developed this code block to accomplish this task:

The code block is returning an error.
Which of the following adjustments does the data scientist need to make to accomplish this task?
An organization is developing a feature repository and is electing to one-hot encode all categorical feature variables. A data scientist suggests that the categorical feature variables should not be one-hot encoded within the feature repository.
Which of the following explanations justifies this suggestion?
Which of the following evaluation metrics is not suitable to evaluate runs in AutoML experiments for regression problems?
A data scientist has produced two models for a single machine learning problem. One of the models performs well when one of the features has a value of less than 5, and the other model performs well when the value of that feature is greater than or equal to 5. The data scientist decides to combine the two models into a single machine learning solution.
Which of the following terms is used to describe this combination of models?
A machine learning engineer has identified the best run from an MLflow Experiment. They have stored the run ID in the run_id variable and identified the logged model name as "model". They now want to register that model in the MLflow Model Registry with the name "best_model".
Which lines of code can they use to register the model associated with run_id to the MLflow Model Registry?