Databricks Databricks-Certified-Data-Engineer-Associate Databricks Certified Data Engineer Associate Exam Exam Practice Test
Total 176 questions
Databricks Certified Data Engineer Associate Exam Questions and Answers
A data engineer wants to create a new table containing the names of customers that live in France.
They have written the following command:

A senior data engineer mentions that it is organization policy to include a table property indicating that the new table includes personally identifiable information (PII).
Which of the following lines of code fills in the above blank to successfully complete the task?
A data engineering team has noticed that their Databricks SQL queries are running too slowly when they are submitted to a non-running SQL endpoint. The data engineering team wants this issue to be resolved.
Which of the following approaches can the team use to reduce the time it takes to return results in this scenario?
In which of the following scenarios should a data engineer use the MERGE INTO command instead of the INSERT INTO command?
Which two components function in the DB platform architecture’s control plane? (Choose two.)
Which of the following describes a benefit of creating an external table from Parquet rather than CSV when using a CREATE TABLE AS SELECT statement?
A data engineer needs to ingest from both streaming and batch sources for a firm that relies on highly accurate data. Occasionally, some of the data picked up by the sensors that provide a streaming input are outside the expected parameters. If this occurs, the data must be dropped, but the stream should not fail.
Which feature of Delta Live Tables meets this requirement?
Which of the following must be specified when creating a new Delta Live Tables pipeline?
A data engineer needs to use a Delta table as part of a data pipeline, but they do not know if they have the appropriate permissions.
In which location can the data engineer review their permissions on the table?
A data engineer is attempting to write Python and SQL in the same command cell and is running into an error The engineer thought that it was possible to use a Python variable in a select statement.
Why does the command fail?
A dataset has been defined using Delta Live Tables and includes an expectations clause:
CONSTRAINT valid_timestamp EXPECT (timestamp > ' 2020-01-01 ' ) ON VIOLATION FAIL UPDATE
What is the expected behavior when a batch of data containing data that violates these constraints is processed?
Which of the following statements regarding the relationship between Silver tables and Bronze tables is always true?
A data engineer needs to apply custom logic to string column city in table stores for a specific use case. In order to apply this custom logic at scale, the data engineer wants to create a SQL user-defined function (UDF).
Which of the following code blocks creates this SQL UDF?
A data engineer is writing a script that is meant to ingest new data from cloud storage. In the event of the Schema change, the ingestion should fail. It should fail until the changes downstream source can be found and verified as intended changes.
Which command will meet the requirements?
A Python file is ready to go into production and the client wants to use the cheapest but most efficient type of cluster possible. The workload is quite small, only processing 10GBs of data with only simple joins and no complex aggregations or wide transformations.
Which cluster meets the requirement?
A data engineer is attempting to drop a Spark SQL table my_table and runs the following command:
DROP TABLE IF EXISTS my_table;
After running this command, the engineer notices that the data files and metadata files have been deleted from the file system.
Which of the following describes why all of these files were deleted?
A data engineer that is new to using Python needs to create a Python function to add two integers together and return the sum?
Which of the following code blocks can the data engineer use to complete this task?
A)
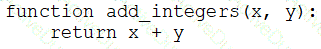
B)

C)
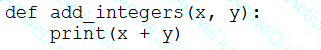
D)
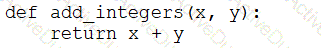
E)
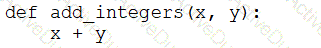
A data engineer wants to delegate day-to-day permission management for the schema main.marketing to the mkt-admins group, without making them workspace admins. They should be able to grant and revoke privileges for other users on objects within that schema.
Which approach aligns with Unity Catalog’s ownership and privilege model?
A data engineer has realized that they made a mistake when making a daily update to a table. They need to use Delta time travel to restore the table to a version that is 3 days old. However, when the data engineer attempts to time travel to the older version, they are unable to restore the data because the data files have been deleted.
Which of the following explains why the data files are no longer present?
A data engineer needs to conduct Exploratory Analysis on data residing in a database that is within the company ' s custom-defined network in the cloud. The data engineer is using SQL for this task.
Which type of SQL Warehouse will enable the data engineer to process large numbers of queries quickly and cost-effectively?
A departing platform owner currently holds ownership of multiple catalogs and controls storage credentials and external locations. The data engineer wants to ensure continuity: transfer catalog ownership to the platform team group, delegate ongoing privilege management, and retain the ability to receive and share data via Delta Sharing .
Which role must be in place to perform these actions across the metastore?
A data engineer has configured a Structured Streaming job to read from a table, manipulate the data, and then perform a streaming write into a new table.

The code block used by the data engineer is below:
Which line of code should the data engineer use to fill in the blank if the data engineer only wants the query to execute a micro-batch to process data every 5 seconds?
Which of the following data lakehouse features results in improved data quality over a traditional data lake?
A Delta Live Table pipeline includes two datasets defined using STREAMING LIVE TABLE. Three datasets are defined against Delta Lake table sources using LIVE TABLE.
The table is configured to run in Development mode using the Continuous Pipeline Mode.
Assuming previously unprocessed data exists and all definitions are valid, what is the expected outcome after clicking Start to update the pipeline?
A data engineer is using the OPTIMIZE command on a Delta table. What happens when OPTIMIZE is run twice on the same table with the same data?
A data engineer needs to create a table in Databricks using data from a CSV file at location /path/to/csv.
They run the following command:

Which of the following lines of code fills in the above blank to successfully complete the task?
Which compute option should be chosen in a scenario where small-scale ad hoc Python scripts need to be run at high frequency and should wind down quickly after these queries have finished running?
A Delta Live Table pipeline includes two datasets defined using STREAMING LIVE TABLE. Three datasets are defined against Delta Lake table sources using LIVE TABLE.
The table is configured to run in Production mode using the Continuous Pipeline Mode.
Assuming previously unprocessed data exists and all definitions are valid, what is the expected outcome after clicking Start to update the pipeline?
Identify how the count_if function and the count where x is null can be used
Consider a table random_values with below data.
What would be the output of below query?
select count_if(col > 1) as count_a. count(*) as count_b.count(col1) as count_c from random_values col1
0
1
2
NULL -
2
3
A data engineer is working on a Databricks project that utilizes cloud storage. The data engineer wants to load several json files from containers on a storage account as soon as the file arrives within the storage account.
Which syntax should the data engineer follow to first load the files into a dataframe and check that it is working as expected using Python?
A data engineer wants to create an external table in Databricks that references data stored in an Azure Data Lake Storage (ADLS) location. The goal is to enable Databricks to access and query this external data without moving it into Databricks-managed storage.
Which step should the data engineer take to successfully create the external table?
What is the maximum output supported by a job cluster to ensure a notebook does not fail?
Which Databricks Asset Bundle format is valid?
A data engineer is working in a Python notebook on Databricks to process data, but notices that the output is not as expected. The data engineer wants to investigate the issue by stepping through the code and checking the values of certain variables during execution.
Which tool should the data engineer use to inspect the code execution and variables in real-time?
In which of the following scenarios should a data engineer select a Task in the Depends On field of a new Databricks Job Task?
A data engineer is managing a data pipeline in Databricks, where multiple Delta tables are used for various transformations. The team wants to track how data flows through the pipeline, including identifying dependencies between Delta tables, notebooks, jobs, and dashboards. The data engineer is utilizing the Unity Catalog lineage feature to monitor this process.
How does Unity Catalog’s data lineage feature support the visualization of relationships between Delta tables, notebooks, jobs, and dashboards?
A data engineer at a company that uses Databricks with Unity Catalog needs to share a collection of tables with an external partner who also uses a Databricks workspace enabled for Unity Catalog. The data engineer decides to use Delta Sharing to accomplish this.
What is the first piece of information the data engineer should request from the external partner to set up Delta Sharing?
Which of the following is stored in the Databricks customer ' s cloud account?
A data engineering project involves processing large batches of data on a daily schedule using ETL. The jobs are resource-intensive and vary in size, requiring a scalable, cost-efficient compute solution that can automatically scale based on the workload.
Which compute approach will satisfy the needs described?
A data engineer is working on a personal laptop and needs to perform complex transformations on data stored in a Delta Lake on cloud storage. The engineer decides to use Databricks Connect to interact with Databricks clusters and work in their local IDE.
How does Databricks Connect enable the engineer to develop, test, and debug code seamlessly on their local machine while interacting with Databricks clusters?
A data engineer is using the following code block as part of a batch ingestion pipeline to read from a composable table:

Which of the following changes needs to be made so this code block will work when the transactions table is a stream source?
A data engineer needs to use a Delta table as part of a data pipeline, but they do not know if they have the appropriate permissions.
In which of the following locations can the data engineer review their permissions on the table?
A data engineer is developing a small proof of concept in a notebook. When running the entire notebook, cluster usage spikes. The data engineer wants to keep the development experience and get real-time results.
Which cluster meets these requirements?
A data organization leader is upset about the data analysis team’s reports being different from the data engineering team’s reports. The leader believes the siloed nature of their organization’s data engineering and data analysis architectures is to blame.
Which of the following describes how a data lakehouse could alleviate this issue?
Which of the following SQL keywords can be used to convert a table from a long format to a wide format?
What is the functionality of AutoLoader in Databricks?
An engineering manager uses a Databricks SQL query to monitor ingestion latency for each data source. The manager checks the results of the query every day, but they are manually rerunning the query each day and waiting for the results.
Which of the following approaches can the manager use to ensure the results of the query are updated each day?
Which of the following tools is used by Auto Loader process data incrementally?
A data engineer needs to determine whether to use the built-in Databricks Notebooks versioning or version their project using Databricks Repos.
Which of the following is an advantage of using Databricks Repos over the Databricks Notebooks versioning?
Which of the following approaches should be used to send the Databricks Job owner an email in the case that the Job fails?
A team creates YAML manifests that declare jobs, resources, and dependencies, then deploys them to Databricks using the Databricks CLI . The deployment succeeds.
Which feature are they using?
A new data engineering team has been assigned to work on a project. The team will need access to database customers in order to see what tables already exist. The team has its own group team.
Which of the following commands can be used to grant the necessary permission on the entire database to the new team?
A Delta Live Table pipeline includes two datasets defined using streaming live table. Three datasets are defined against Delta Lake table sources using live table.
The table is configured to run in Production mode using the Continuous Pipeline Mode.
What is the expected outcome after clicking Start to update the pipeline assuming previously unprocessed data exists and all definitions are valid?
Total 176 questions