A stream called TRANSACTIONS_STM is created on top of a transactions table in a continuous pipeline running in Snowflake. After a couple of months, the TRANSACTIONS table is renamed transactiok3_raw to comply with new naming standards
What will happen to the TRANSACTIONS _STM object?
Which stages support external tables?
A Data Engineer is implementing a near real-time ingestionpipeline to toad data into Snowflake using the Snowflake Kafka connector. There will be three Kafka topics created.
……snowflake objects are created automatically when the Kafka connector starts? (Select THREE)
A Data Engineer is building a pipeline to transform a 1 TD tab e by joining it with supplemental tables The Engineer is applying filters and several aggregations leveraging Common TableExpressions (CTEs) using a size Medium virtual warehouse in a single query in Snowflake.
After checking the Query Profile, what is the recommended approach to MAXIMIZE performance of this query if the Profile shows data spillage?
How can the following relational data be transformed into semi-structured data using the LEAST amount of operational overhead?

A Data Engineer is investigating a query that is taking a long time to return The Query Profile shows the following:
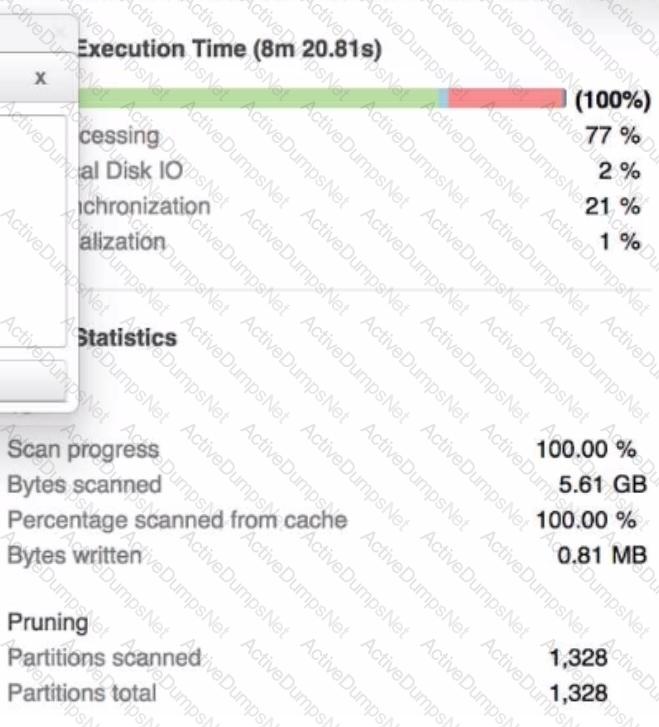
What step should the Engineer take to increase the query performance?
A Data Engineer has created table t1 with datatype VARIANT:
create or replace table t1 (cl variant);
The Engineer has loaded the following JSON data set. which has information about 4 laptop models into the table:

The Engineer now wants to query that data set so that results are shown as normal structured data. The result should be 4 rows and 4 columns without the double quotes surrounding the data elements in the JSON data.
The result should be similar to the use case where the data was selected from a normal relational table z2 where t2 has string data type columns model__id. model, manufacturer, and =iccisi_r.an=. and is queried with the SQL clause select * from t2;
Which select command will produce the correct results?
A)

B)
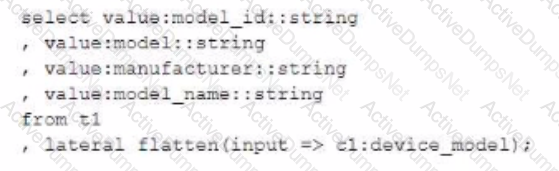
C)

D)

What is a characteristic of the operations of streams in Snowflake?
A database contains a table and a stored procedure defined as.

No other operations are affecting the log_table.
What will be the outcome of the procedure call?
At what isolation level are Snowflake streams?
The following code is executed ina Snowflake environment with the default settings:

What will be the result of the select statement?
A Data Engineer is evaluating the performance of a query in a development environment.
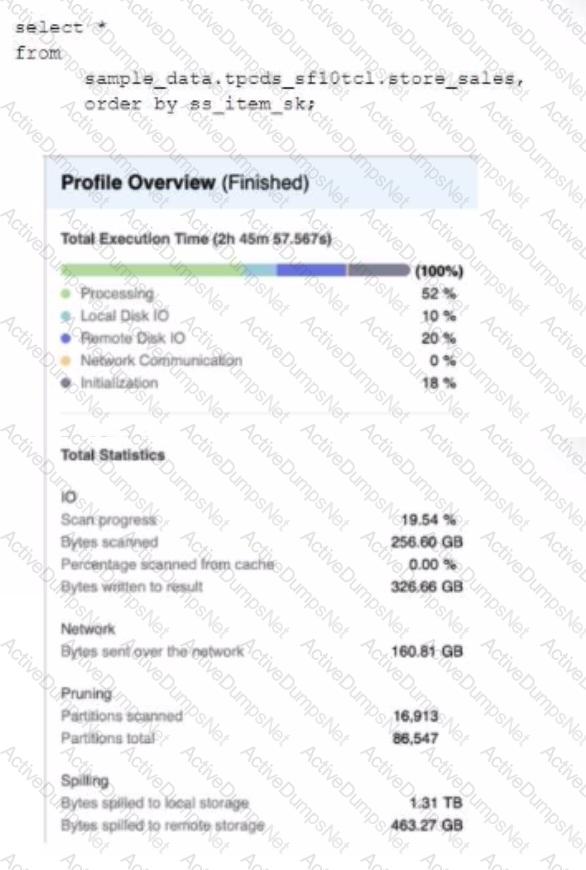
Based on the Query Profile what are some performance tuning options the Engineer can use? (Select TWO)
A company built a sales reporting system with Python, connecting to Snowflake using the Python Connector. Based on the user's selections, the system generates the SQL queries needed to fetch the data for the report First it gets the customers that meet the given query parameters (on average 1000 customer records for each report run) and then it loops the customer records sequentially Inside that loop it runs the generated SQL clause for the current customer to get the detailed data for that customer number from the sales data table
When the Data Engineer tested the individual SQL clauses they were fast enough (1 second to get the customers 0 5 second to get the sales data for one customer) but the total runtime of the report is too long
How can this situation be improved?
What is a characteristic of the use of external tokenization?
What is the purpose of the BUILD_FILE_URL function in Snowflake?
A Data Engineer wants to check the status of a pipe named my_pipe. The pipe is inside a database named test and a schema named Extract (case-sensitive).
Which querywill provide the status of the pipe?
A Data Engineer wants to create a new development database (DEV) as a clone of the permanent production database (PROD) There is a requirement to disable Fail-safe for all tables.
Which command will meet these requirements?
Which callback function is required within a JavaScript User-Defined Function (UDF) for it to execute successfully?
A Data Engineer needs to know the details regarding the micro-partition layout for a table named invoice using a built-in function.
Which query will provide this information?