Databricks Databricks-Certified-Professional-Data-Engineer Databricks Certified Data Engineer Professional Exam Exam Practice Test
Total 202 questions
Databricks Certified Data Engineer Professional Exam Questions and Answers
A data engineer is configuring Delta Sharing for a Databricks-to-Databricks scenario to optimize read performance. The recipient needs to perform time travel queries and streaming reads on shared sales data.
Which configuration will provide the optimal performance while enabling these capabilities?
A data engineering team uses Databricks Lakehouse Monitoring to track the percent_null metric for a critical column in their Delta table.
The profile metrics table (prod_catalog.prod_schema.customer_data_profile_metrics) stores hourly percent_null values.
The team wants to:
Trigger an alert when the daily average of percent_null exceeds 5% for three consecutive days .
Ensure that notifications are not spammed during sustained issues.
Options:
A data engineer created a daily batch ingestion pipeline using a cluster with the latest DBR version to store banking transaction data, and persisted it in a MANAGED DELTA table called prod.gold.all_banking_transactions_daily. The data engineer is constantly receiving complaints from business users who query this table ad hoc through a SQL Serverless Warehouse about poor query performance. Upon analysis, the data engineer identified that these users frequently use high-cardinality columns as filters. The engineer now seeks to implement a data layout optimization technique that is incremental, easy to maintain, and can evolve over time.
Which command should the data engineer implement?
A junior data engineer on your team has implemented the following code block.
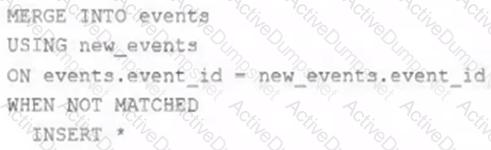
The view new_events contains a batch of records with the same schema as the events Delta table. The event_id field serves as a unique key for this table.
When this query is executed, what will happen with new records that have the same event_id as an existing record?
The data engineering team is migrating an enterprise system with thousands of tables and views into the Lakehouse. They plan to implement the target architecture using a series of bronze, silver, and gold tables. Bronze tables will almost exclusively be used by production data engineering workloads, while silver tables will be used to support both data engineering and machine learning workloads. Gold tables will largely serve business intelligence and reporting purposes. While personal identifying information (PII) exists in all tiers of data, pseudonymization and anonymization rules are in place for all data at the silver and gold levels.
The organization is interested in reducing security concerns while maximizing the ability to collaborate across diverse teams.
Which statement exemplifies best practices for implementing this system?
A Spark job is taking longer than expected. Using the Spark UI, a data engineer notes that the Min, Median, and Max Durations for tasks in a particular stage show the minimum and median time to complete a task as roughly the same, but the max duration for a task to be roughly 100 times as long as the minimum.
Which situation is causing increased duration of the overall job?
While reviewing a query ' s execution in the Databricks Query Profiler, a data engineer observes that the Top Operators panel shows a Sort operator with high Time Spent and Memory Peak metrics. The Spark UI also reports frequent data spilling .
How should the data engineer address this issue?
A Structured Streaming job deployed to production has been experiencing delays during peak hours of the day. At present, during normal execution, each microbatch of data is processed in less than 3 seconds. During peak hours of the day, execution time for each microbatch becomes very inconsistent, sometimes exceeding 30 seconds. The streaming write is currently configured with a trigger interval of 10 seconds.
Holding all other variables constant and assuming records need to be processed in less than 10 seconds, which adjustment will meet the requirement?
A platform team lead is responsible for automating SQL Warehouse usage attribution across business units. They need to identify warehouse usage at the individual user level and share a daily usage report with an executive team that includes business leaders from multiple departments.
How should the platform lead generate an automated report that can be shared daily?
A security analytics pipeline must enrich billions of raw connection logs with geolocation data. The join hinges on finding which IPv4 range each event’s address falls into.
Table 1: network_events (≈ 5 billion rows)
event_id ip_int
42 3232235777
Table 2: ip_ranges (≈ 2 million rows)
start_ip_int end_ip_int country
3232235520 3232236031 US
The query is currently very slow:
SELECT n.event_id, n.ip_int, r.country
FROM network_events n
JOIN ip_ranges r
ON n.ip_int BETWEEN r.start_ip_int AND r.end_ip_int;
Question:
Which change will most dramatically accelerate the query while preserving its logic?
A data engineer is tasked with ensuring that a Delta table in Databricks continuously retains deleted files for 15 days (instead of the default 7 days), in order to permanently comply with the organization’s data retention policy.
Which code snippet correctly sets this retention period for deleted files?
A data engineer is running a groupBy aggregation on a massive user activity log grouped by user_id. A few users have millions of records, causing task skew and long runtimes.
Which technique will fix the skew in this aggregation?
An upstream system is emitting change data capture (CDC) logs that are being written to a cloud object storage directory. Each record in the log indicates the change type (insert, update, or delete) and the values for each field after the change. The source table has a primary key identified by the field pk_id .
For auditing purposes, the data governance team wishes to maintain a full record of all values that have ever been valid in the source system. For analytical purposes, only the most recent value for each record needs to be recorded. The Databricks job to ingest these records occurs once per hour, but each individual record may have changed multiple times over the course of an hour.
Which solution meets these requirements?
The business reporting team requires that data for their dashboards be updated every hour. The total processing time for the pipeline that extracts, transforms, and loads the data for their pipeline runs in 10 minutes. Assuming normal operating conditions, which configuration will meet their service-level agreement requirements with the lowest cost?
A data engineer, while designing a Pandas UDF to process financial time-series data with complex calculations that require maintaining state across rows within each stock symbol group, must ensure the function is efficient and scalable. Which approach will solve the problem with minimum overhead while preserving data integrity?
A data engineer is creating a daily reporting job. There are two reporting notebooks—one for weekdays and one for weekends. An “if/else condition” task is configured as {{job.start_time.is_weekday}} == true to route the job to either the weekday or weekend notebook tasks. The same job would be used across multiple time zones.
Which action should a senior data engineer take upon reviewing the job to merge or reject the pull request?
A data architect is designing a Databricks solution to efficiently process data for different business requirements.
In which scenario should a data engineer use a materialized view compared to a streaming table ?
An hourly batch job is configured to ingest data files from a cloud object storage container where each batch represent all records produced by the source system in a given hour. The batch job to process these records into the Lakehouse is sufficiently delayed to ensure no late-arriving data is missed. The user_id field represents a unique key for the data, which has the following schema:
user_id BIGINT, username STRING, user_utc STRING, user_region STRING, last_login BIGINT, auto_pay BOOLEAN, last_updated BIGINT
New records are all ingested into a table named account_history which maintains a full record of all data in the same schema as the source. The next table in the system is named account_current and is implemented as a Type 1 table representing the most recent value for each unique user_id .
Assuming there are millions of user accounts and tens of thousands of records processed hourly, which implementation can be used to efficiently update the described account_current table as part of each hourly batch job?
A data engineer is masking a column containing email addresses. The goal is to produce output strings of identical length for all rows, while generating different outputs for different email values .
Which SQL function should be used to achieve this?
A data engineer is designing a Lakeflow Spark Declarative Pipeline to process streaming order data. The pipeline uses Auto Loader to ingest data and must enforce data quality by ensuring customer_id is not null and amount is greater than zero. Invalid records should be dropped. Which Lakeflow Spark Declarative Pipelines configuration implements this requirement using Python?
A junior data engineer has been asked to develop a streaming data pipeline with a grouped aggregation using DataFrame df. The pipeline needs to calculate the average humidity and average temperature for each non-overlapping five-minute interval. Incremental state information should be maintained for 10 minutes for late-arriving data.
Streaming DataFrame df has the following schema:
" device_id INT, event_time TIMESTAMP, temp FLOAT, humidity FLOAT "
Code block:

Choose the response that correctly fills in the blank within the code block to complete this task.
The DevOps team has configured a production workload as a collection of notebooks scheduled to run daily using the Jobs UI. A new data engineering hire is onboarding to the team and has requested access to one of these notebooks to review the production logic.
What are the maximum notebook permissions that can be granted to the user without allowing accidental changes to production code or data?
Which approach demonstrates a modular and testable way to use DataFrame.transform for ETL code in PySpark?
A data engineering team is configuring access controls in Databricks Unity Catalog . They grant the SELECT privilege on the sales catalog to the analyst_group, expecting that members of this group will automatically have SELECT access to all current and future schemas, tables, and views within the catalog.
What describes the privilege inheritance behavior in Unity Catalog?
Which statement describes Delta Lake optimized writes?
Which Python variable contains a list of directories to be searched when trying to locate required modules?
A data team ' s Structured Streaming job is configured to calculate running aggregates for item sales to update a downstream marketing dashboard. The marketing team has introduced a new field to track the number of times this promotion code is used for each item. A junior data engineer suggests updating the existing query as follows: Note that proposed changes are in bold.

Which step must also be completed to put the proposed query into production?
A Databricks SQL dashboard has been configured to monitor the total number of records present in a collection of Delta Lake tables using the following query pattern:
SELECT COUNT (*) FROM table -
Which of the following describes how results are generated each time the dashboard is updated?
Two data engineers are working on the same Databricks notebook in separate branches. Both have edited the same section of code. When one tries to merge the other’s branch into their own using the Databricks Git folders UI, a merge conflict occurs on that notebook file. The UI highlights the conflict and presents options for resolution.
How should the data engineers resolve this merge conflict using Databricks Git folders?
A data engineer is implementing Unity Catalog governance for a multi-team environment. Data scientists need interactive clusters for basic data exploration tasks, while automated ETL jobs require dedicated processing.
How should the data engineer configure cluster isolation policies to enforce least privilege and ensure Unity Catalog compliance?
A member of the data engineering team has submitted a short notebook that they wish to schedule as part of a larger data pipeline. Assume that the commands provided below produce the logically correct results when run as presented.

Which command should be removed from the notebook before scheduling it as a job?
An external object storage container has been mounted to the location /mnt/finance_eda_bucket .
The following logic was executed to create a database for the finance team:

After the database was successfully created and permissions configured, a member of the finance team runs the following code:

If all users on the finance team are members of the finance group, which statement describes how the tx_sales table will be created?
An analytics team wants to run a short-term experiment in Databricks SQL on the customer transactions Delta table (about 20 billion records) created by the data engineering team. Which strategy should the data engineering team use to ensure minimal downtime and no impact on the ongoing ETL processes?
In order to prevent accidental commits to production data, a senior data engineer has instituted a policy that all development work will reference clones of Delta Lake tables. After testing both deep and shallow clone, development tables are created using shallow clone.
A few weeks after initial table creation, the cloned versions of several tables implemented as Type 1 Slowly Changing Dimension (SCD) stop working. The transaction logs for the source tables show that vacuum was run the day before.
Why are the cloned tables no longer working?
Two of the most common data locations on Databricks are the DBFS root storage and external object storage mounted with dbutils.fs.mount().
Which of the following statements is correct?
A Delta Lake table was created with the below query:

Realizing that the original query had a typographical error, the below code was executed:
ALTER TABLE prod.sales_by_stor RENAME TO prod.sales_by_store
Which result will occur after running the second command?
The data engineer team is configuring environment for development testing, and production before beginning migration on a new data pipeline. The team requires extensive testing on both the code and data resulting from code execution, and the team want to develop and test against similar production data as possible.
A junior data engineer suggests that production data can be mounted to the development testing environments, allowing pre production code to execute against production data. Because all users have
Admin privileges in the development environment, the junior data engineer has offered to configure permissions and mount this data for the team.
Which statement captures best practices for this situation?
Which statement describes the default execution mode for Databricks Auto Loader?
A data engineer is tasked with building a nightly batch ETL pipeline that processes very large volumes of raw JSON logs from a data lake into Delta tables for reporting. The data arrives in bulk once per day, and the pipeline takes several hours to complete. Cost efficiency is important, but performance and reliability of completing the pipeline are the highest priorities.
Which type of Databricks cluster should the data engineer configure?
A junior data engineer is working to implement logic for a Lakehouse table named silver_device_recordings. The source data contains 100 unique fields in a highly nested JSON structure.
The silver_device_recordings table will be used downstream for highly selective joins on a number of fields, and will also be leveraged by the machine learning team to filter on a handful of relevant fields, in total, 15 fields have been identified that will often be used for filter and join logic.
The data engineer is trying to determine the best approach for dealing with these nested fields before declaring the table schema.
Which of the following accurately presents information about Delta Lake and Databricks that may Impact their decision-making process?
A Delta Lake table representing metadata about content from user has the following schema:
user_id LONG, post_text STRING, post_id STRING, longitude FLOAT, latitude FLOAT, post_time TIMESTAMP, date DATE
Based on the above schema, which column is a good candidate for partitioning the Delta Table?
A data engineering team is migrating off its legacy Hadoop platform. As part of the process, they are evaluating storage formats for performance comparison. The legacy platform uses ORC and RCFile formats. After converting a subset of data to Delta Lake , they noticed significantly better query performance. Upon investigation, they discovered that queries reading from Delta tables leveraged a Shuffle Hash Join , whereas queries on legacy formats used Sort Merge Joins . The queries reading Delta Lake data also scanned less data.
Which reason could be attributed to the difference in query performance?
Which statement regarding stream-static joins and static Delta tables is correct?
Which method can be used to determine the total wall-clock time it took to execute a query?
A query is taking too long to run. After investigating the Spark UI, the data engineer discovered a significant amount of disk spill . The compute instance being used has a core-to-memory ratio of 1:2.
What are the two steps the data engineer should take to minimize spillage? (Choose 2 answers)
A table in the Lakehouse named customer_churn_params is used in churn prediction by the machine learning team. The table contains information about customers derived from a number of upstream sources. Currently, the data engineering team populates this table nightly by overwriting the table with the current valid values derived from upstream data sources.
The churn prediction model used by the ML team is fairly stable in production. The team is only interested in making predictions on records that have changed in the past 24 hours.
Which approach would simplify the identification of these changed records?
An upstream system has been configured to pass the date for a given batch of data to the Databricks Jobs API as a parameter. The notebook to be scheduled will use this parameter to load data with the following code:
df = spark.read.format( " parquet " ).load(f " /mnt/source/(date) " )
Which code block should be used to create the date Python variable used in the above code block?
The data engineering team has configured a Databricks SQL query and alert to monitor the values in a Delta Lake table. The recent_sensor_recordings table contains an identifying sensor_id alongside the timestamp and temperature for the most recent 5 minutes of recordings.
The below query is used to create the alert:
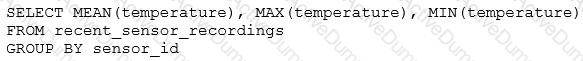
The query is set to refresh each minute and always completes in less than 10 seconds. The alert is set to trigger when mean (temperature) > 120 . Notifications are triggered to be sent at most every 1 minute.
If this alert raises notifications for 3 consecutive minutes and then stops, which statement must be true?
A developer has successfully configured credential for Databricks Repos and cloned a remote Git repository. Hey don not have privileges to make changes to the main branch, which is the only branch currently visible in their workspace.
Use Response to pull changes from the remote Git repository commit and push changes to a branch that appeared as a changes were pulled.
A Delta Lake table was created with the below query:

Consider the following query:
DROP TABLE prod.sales_by_store -
If this statement is executed by a workspace admin, which result will occur?
Which statement describes integration testing?
A company has a task management system that tracks the most recent status of tasks. The system takes task events as input and processes events in near real-time using Lakeflow Declarative Pipelines. A new task event is ingested into the system when a task is created or the task status is changed. Lakeflow Declarative Pipelines provides a streaming table (tasks_status) for BI users to query.
The table represents the latest status of all tasks and includes 5 columns:
task_id (unique for each task)
task_name
task_owner
task_status
task_event_time
The table enables three properties: deletion vectors, row tracking, and change data feed (CDF).
A data engineer is asked to create a new Lakeflow Declarative Pipeline to enrich the tasks_status table in near real-time by adding one additional column representing task_owner’s department, which can be looked up from a static dimension table (employee).
How should this enrichment be implemented?
The DevOps team has configured a production workload as a collection of notebooks scheduled to run daily using the Jobs Ul. A new data engineering hire is onboarding to the team and has requested access to one of these notebooks to review the production logic.
What are the maximum notebook permissions that can be granted to the user without allowing accidental changes to production code or data?
The Databricks CLI is used to trigger a run of an existing job by passing the job_id parameter. The response indicating the job run request was submitted successfully includes a field run_id. Which statement describes what the number alongside this field represents?
The data engineering team maintains the following code:

Assuming that this code produces logically correct results and the data in the source tables has been de-duplicated and validated, which statement describes what will occur when this code is executed?
A data engineer is attempting to execute the following PySpark code:
df = spark.read.table( " sales " )
result = df.groupBy( " region " ).agg(sum( " revenue " ))
However, upon inspecting the execution plan and profiling the Spark job, they observe excessive data shuffling during the aggregation phase.
Which technique should be applied to reduce shuffling during the groupBy aggregation operation?
Which configuration parameter directly affects the size of a spark-partition upon ingestion of data into Spark?
Which of the following is true of Delta Lake and the Lakehouse?
A transactions table has been liquid clustered on the columns product_id, user_id, and event_date.
Which operation lacks support for cluster on write?
A data engineer is designing a pipeline in Databricks that processes records from a Kafka stream where late-arriving data is common.
Which approach should the data engineer use?
Total 202 questions